



第二节 模型界定
结构方程模型是由一系列的变量与参数所组成,联结变量与参数的工作则由数学方程式承担。将研究者所关心的变量与参数通过统计模型来描述,进而加以估计分析,即是结构方程模型所有的模型界定(邱皓政、林碧芳,2009)。
一、潜变量的设定
结构方程模型主要研究潜变量之间的结构关系,潜变量的设定是模型建立的基础。一般有两种方法来设定潜变量:一是从理论出发的潜变量构建思路,是指按照研究既有理论或经验设定;二是从数据出发的潜变量构建思路,是指通过因子分析从数据中提炼潜变量。
通过文献综述了解到,与旅游社会影响相似,会展社会影响存在如下分类:个人会展社会影响感知和社区会展社会影响感知,而这两个层面的会展社会影响感知又可以区分为积极的个人会展社会影响感知、消极的个人会展社会影响感知以及积极的社区会展社会影响感知和消极的社区会展社会影响感知。这四个方面的影响感知都是潜变量,必须通过一些可观测的变量来测量。
另外,本章也从数据出发构建潜变量。第三章通过探索性因子分析构建的会展社会影响尺度(SISC)由个人收益、社区收益和成本感知3个潜变量构成,基本上与国内外旅游影响研究的结构相似。
二、可测变量的设定
可测变量是用来度量潜变量的指标,是可以被直接观测或测量的变量。通过文献综述,参照旅游及节事等相近领域的研究结论,结合第三章SISC构建的结果,本章中的潜变量分别有3个可测变量。个人收益潜变量的可测变量有:广交会“促进了广州居民与参展者的文化交流”、“提高了广州居民的普通话和英语水平”以及“使广州居民的文明程度和好客度增加”。社区收益潜变量的可测变量有:广交会“使广州的市容更漂亮了”、“使广州的公共设施维护得更好了”以及“提升了广州的国际化大都市形象”。成本感知潜变量的可测变量有:“使酗酒、故意破坏等不良行为增加了”、“使展馆附近的噪声和垃圾增加了”以及“使广州房价和租赁成本上涨了”。
三、假设模型结构
根据讨论的潜变量和可测变量的关系,可以建立假设模型如图5-1和表5-1所示。
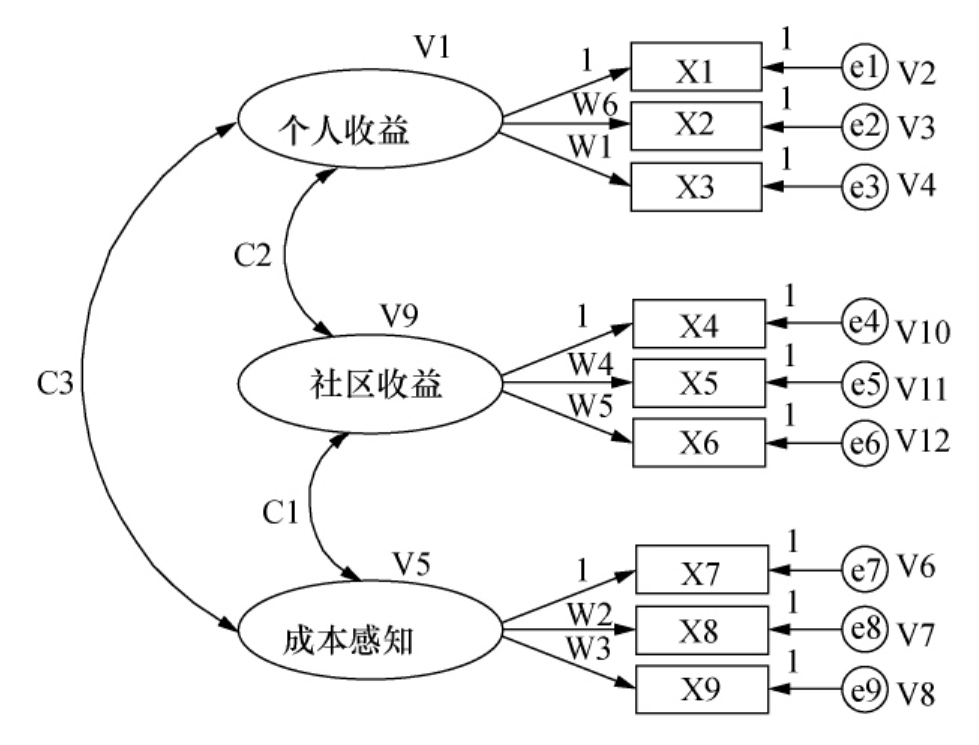
图5-1 假设模型结构
表5-1 假设模型变量对应表
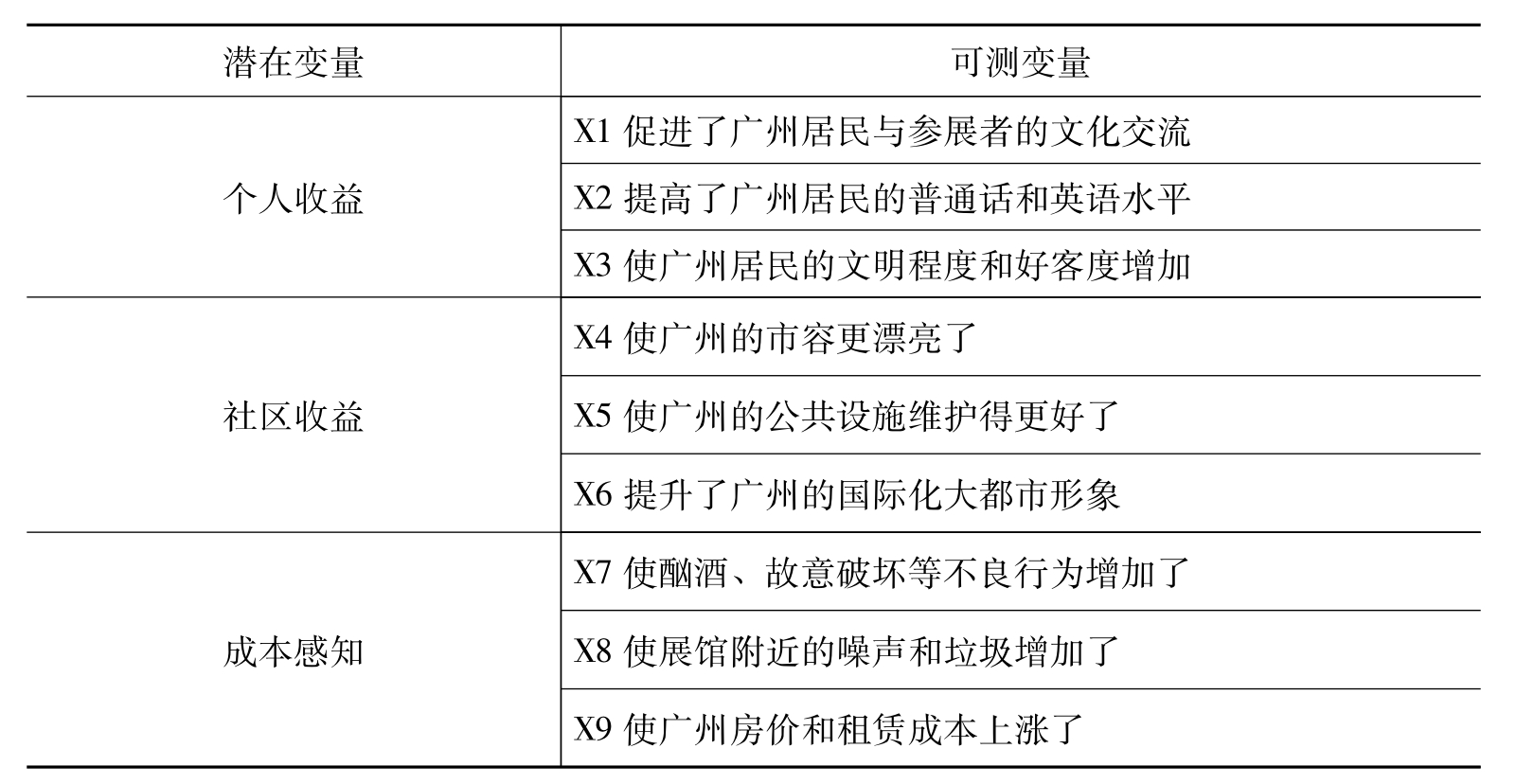
四、数据采集
2009年2月25日至3月5日,在天河区和海珠区进行了第三次问卷调查,这次调查发放问卷450份,回收367份有效问卷,回收率为81.6%。这次问卷的主要目的是进行验证性因子分析,因此问卷结构完全采用SISC的结论,即3个维度9个测量项目,问卷采用了李克特5分量度。另外,设置了一些人口统计学变量,以供将来进行研究对比。表5-2是第三次问卷调查的描述统计量。
表5-2 CFA样本的描述统计量(n= 367)
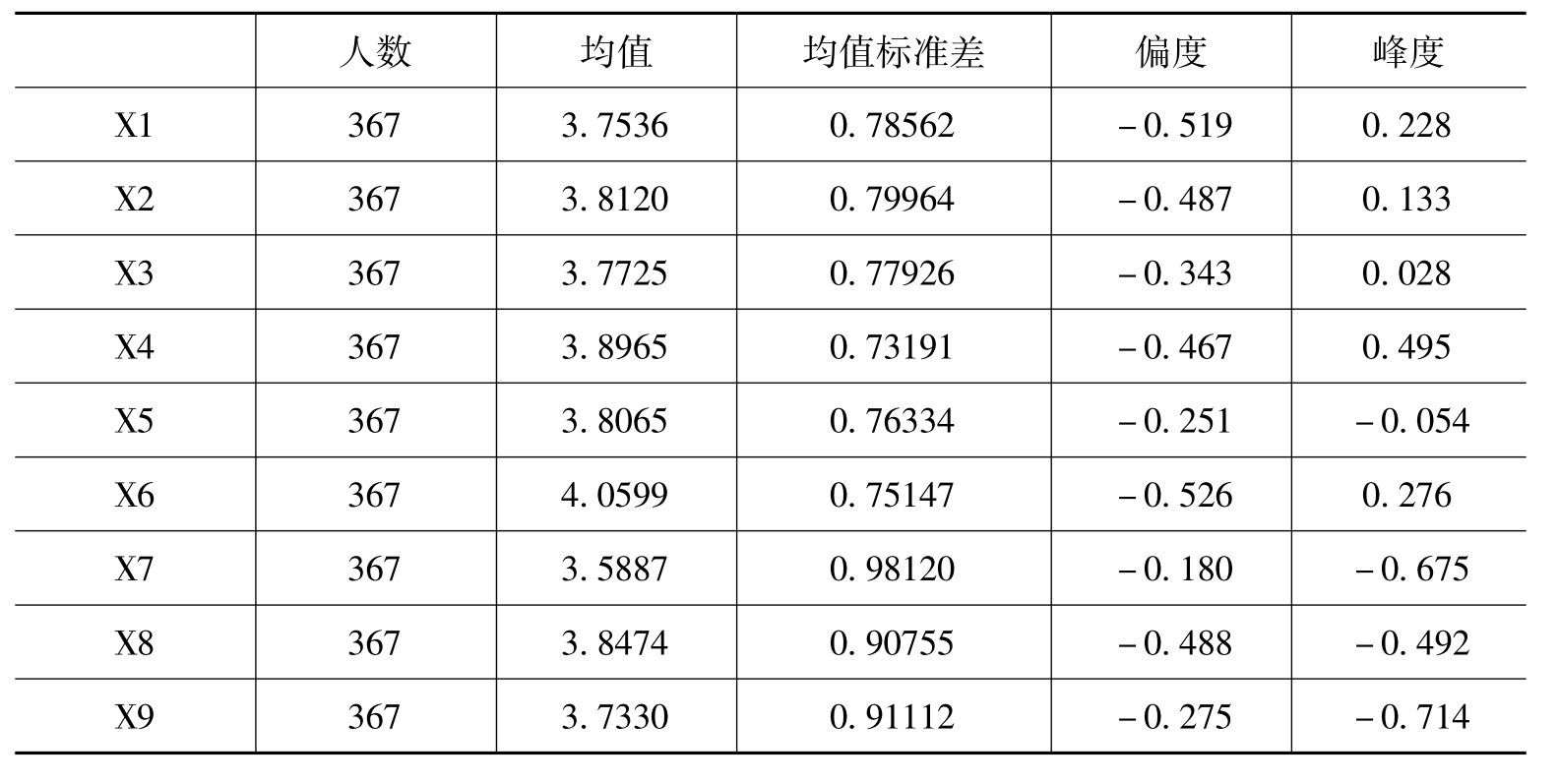
从表5-2来看,9个测量项目(X1~X9)中,前6个项目是积极社会影响项目,均值在3.7536~4.0599分之间。其中,得分最高的项目是X6“提升了广州的国际化大都市形象”,得分最低的项目是X1“促进了广州居民与参展者的文化交流”。后3个项目是消极社会影响项目,均值在3.5887~3.8474分之间。其中,得分最高的项目是X8“使展馆附近的噪声和垃圾增加了”,得分最低的项目是X7“使酗酒、故意破坏等不良行为增加了”。这说明,样本中的广州居民最赞同的广交会积极社会影响是对广州城市形象的提升,但是认为广交会产生的主客文化交流效应并不太强。
五、缺失值的处理
在进行验证性因子分析之前,利用SPSS 15.0对CFA样本的缺失值做了适当的处理。如果对样本的缺失值不做适当的处理,就可能产生“非正定矩阵”(Nonpositive Definitive Matrices)的问题,AMOS可能无法识别模型。本次研究中缺失值的替换方法采用“序列均值”替换方法(某题项所有答题者数值的平均值)。
六、模型识别的t规则
模型识别就是考察模型的待估计参数是否能够有效估计。在结构方程模型中,模型的待估参数由模型结构中对方差—协方差决定。t规则识别法是指:
t≤1/2(p+q)(p+q+1)
式中,t是待估计的参数的个数; p是内生可测变量的个数; q是外生可测变量的个数。t规则识别法是模型能否被识别的一个必要而非充分条件。
在假设模型(见图5-1)中,自由参数包括3个共变异数(C1、C2、C3),12个变异数(V1、V2、V3、V4、V5、V6、V7、V8、V9、V10、V11、V12),6个回归系数(即因素负荷量,包括W 1、W 2、W 3、W 4、W 5、W 6)。因此,t就等于3+ 12+ 6= 21。
又由于假设模型有9个观测变量,9个内生变量。因此,CFA样本提供的共变异矩阵之资料点数= 1/2×(9+ 9)×(9+ 9+ 1)= 171。
t= 21<171
这说明从模型识别的t规则来看,假设模型是有可能被识别的。
七、数据的信度和效度检验
(一)数据的信度检验
信度(reliability)指测量结果(数据)一致性或稳定性的程度。本章采用SPSS 15.0研究数据的内部一致性,结果(见表5-3)显示克朗巴赫α系数为0.739,说明本章中所使用的数据具有较好的信度。
表5-3 CFA数据的信度分析结果

(二)数据的效度检验
效度(validity)指测量工具能够正确测量出所要测量的特质的程度,分为内容效度(content validity)、效标效度(criterion validity)和结构效度(construct validity)三个主要类型。内容效度是指测量目标与测量内容之间的适合性与相符性。效标效度指用几种不同的测量方式或不同的指标对同一变量进行测量,并将其中的一种方式作为准则(效标),用其他的方式或指标与这个准则作比较,如果其他方式或指标也有效,那么这个测量即具备效标效度。结构效度指测量工具反映概念或命题的程度,即反映内部结构的程度,也就是说如果问卷调查结果能够测量其理论特征,调查结果与理论预期一致,则认为数据具有较高的结构效度(易丹辉,2008)。
内容效度和效标效度往往通过专家定性研究或具有公认的效标测量加以判定,结构效度可以通过模型系数来评价。如果模型假设的潜变量之间的关系以及潜变量与可测变量之间的关系合理,非标准化系数应当具有显著的统计意义。从表5-4可以看出在99%的置信水平下,所有非标准化系数具有统计显著性,说明模型所使用数据的整体结构效度较好。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。









