



6.3 资源下载器设计
前面我们已经详细地介绍了网络爬虫技术,以及Nutch和Heritrix的工作原理。这对我们研究设计自己的爬虫工具,甚至是信息检索系统有十分积极的作用。下面我们将针对叙词本体演化实验的需要,设计自己的网络信息源下载程序,并利用此程序获取特定的信息源为后续工作做好准备。
6.3.1 数据源的筛选
由于叙词本体是用于文献或者网络资源的标引,因此需要更新的概念必须为规范化的。基于《中国图书馆分类主题词表》的某个特定领域的叙词,我们构建了基础本体。中国期刊全文数据库文献总量十分丰富,文献类型多样,包括:学术期刊、博士学位论文、优秀硕士学位论文、工具书、重要会议论文、年鉴、专著、报纸、专利、标准、科技成果、知识元、哈佛商业评论数据库、古籍等,还可以与德国Springer公司期刊库等外文资源统一检索。因此我们选择中国期刊全文数据库中该领域相关文献作为我们叙词本体演化的网络资源。用于标引的叙词是最能够表达文献主题的词汇,然而这类词汇就集中在文献的标题、关键词以及摘要中,并且这些信息就呈现在中国期刊网的网页上,因此在整个过程中我们可以不用提取整个PDF文档。
我们已经分析过中国期刊网的文献描述页面对于提取新词汇以及新关系是一种极其重要的资源,因此我们的爬虫系统主要是要爬取中国期刊网中描述文献的网页。
通过分析中国期刊网的网址,我们发现针对不同的期刊杂志以及不同的日期,网址有不同的参数filename以及dbname。如《图书馆建设》2008年8月第33篇文章,其网址为http:// epub. cnki.net/grid2008/detail.aspx? filename= TSGJ 200808033&dbname=CJFDT2008。因此,我们只需要对特定网页进行抓取即可,而无需通过网页的超级链接再进行深度的爬取。图6-36为爬虫系统的流程图。
如流程图6-36所示,爬虫系统中有两次循环,一个是对中国期刊网中所有需要爬取的期刊进行循环,另一个是对每一种期刊还要对每一篇文章进行循环。对于哪些期刊需要抓取,则需要工作人员根据需要更新的领域以及该领域所存在的期刊进行界定,同时也需要对期刊的期数进行界定。如果系统需要每个月对叙词本体更新,那么只需要抓取最近一个月的文献即可,而如果系统是每两个月或者更长时间对叙词本体进行更新,那么则需要对期数也进行一次循环(图中没有画出)。为了减少工作人员的工作的复杂度,我们建议每个月抓取中国期刊网上的文献描述网页。以上这些关键参数的设置在本书第10章系统实现中将会详细地介绍。
6.3.2 代码解析
根据上节中介绍的爬虫程序设计思路,我们将对设计出来的源代码进行详细的解析。
package org.webpagedownloader;
import java.net.URL;
import java.net.URLConnection;
import java.util.Scanner;
import java. io.FileOutputStream;
import java. io. IOException;
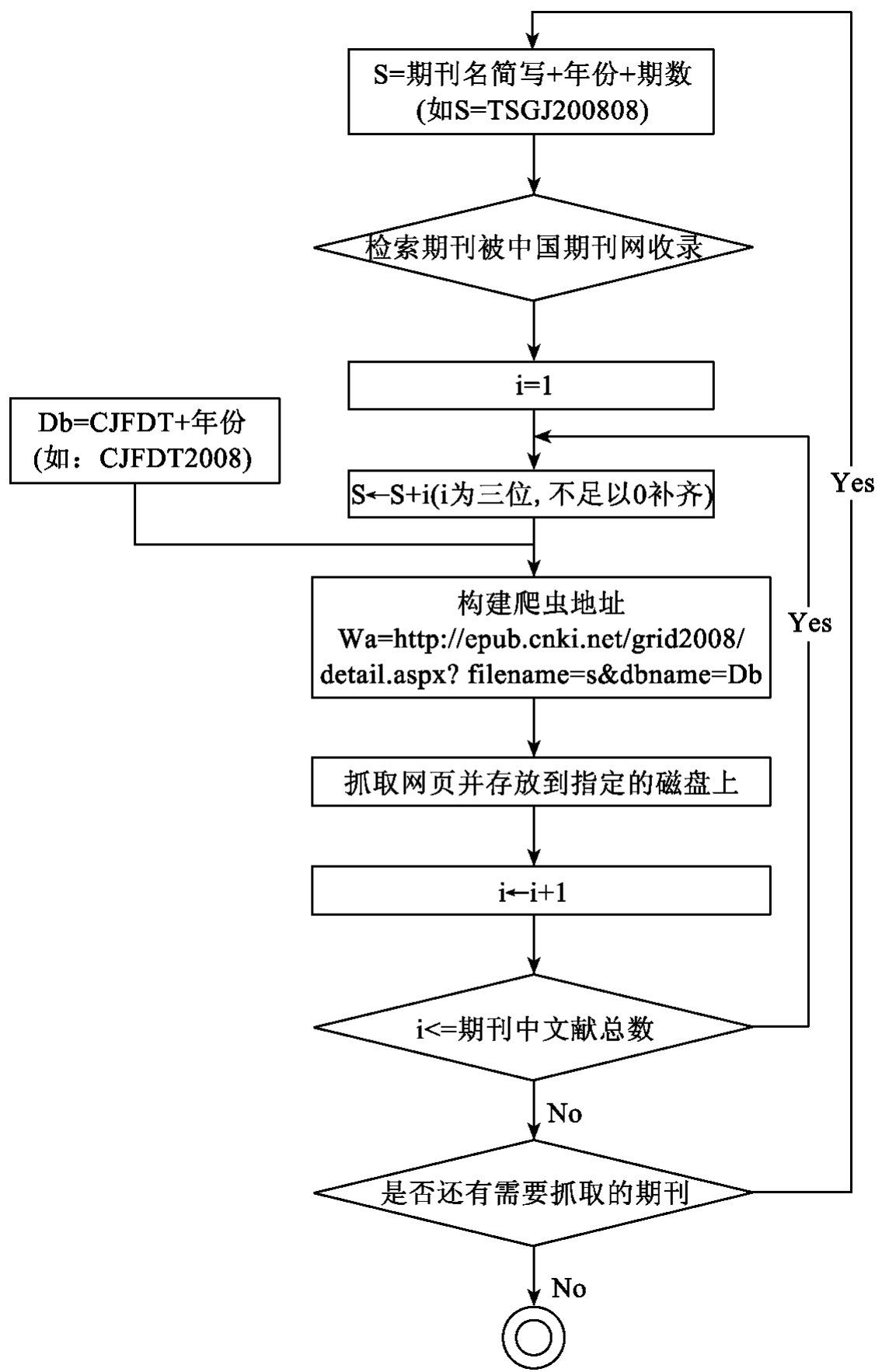
图6-36 爬虫程序的流程图
import java. io. InputStream;
import java. io.OutputStreamWriter;
public class MyDownload{
public static void main(String[]args){
download dl= new download();
dl.start();
}
}
/**
*类download
*功能描述:用于下载CNKI学术期刊网上指定URL范围的文献描述页面,并将页面保存至指定文件夹。
*结构描述:
*类download继承Thread类,重写Thread类的run()方法,在run()方法中实现网页的下载和保存。
*具有下载和保存网页信息资源所需要的私有属性以及对这些属性进行基本的读写操作的* getXX()和setXX()方法。
*使用方法:实例化类download,调用方法start()即可实现网页信息资源下载的功能。
*/
class download extends Thread{
/**
*声明类的私有属性,包括网页下载所需的参数和下载过程涉及的对象。
*网页下载所需参数:
*(1)h,类型为int,表示文献描述页面URL的初始变动部分,对该初始值进行递增后
*与URL固定部分组成新的URL即是另一文献资源的描述页面的URL。
*(2)charset,类型为String,表示下载的HTML页面的编码字符集,如设置为"UTF-8"或"GBK"等则可识别中文字符。
*(3)pageHtmlCode,类型为String,用于保存爬取到的网页信息资源的HTML代码。
*(4)urlString,类型为String,用来表示目标文献描述页面的URL。
*下载过程涉及的对象:
*(1)ism,属于InputStream对象,用于获取目标文献描述页面的网页输入流。
*(2)url,属于URL对象,利用目标文献页面的URL实例URL对象,该对象可创建URLConnection对象,通过URLConnection对象实现网页输入流的捕获。
*(3)connection,属于URLConnection对象,用于捕获网页输入流。
*(4) in,属于Scanner对象,对输入流以特定字符集扫描。
*/
//文献描述页面URL变动部分的初始值为828101
private int h= 828101;
private String pageHtmlCode="";
//规定下载的描述文献的HTML页面的编码字符集为UTF-8
private String charset="utf-8";
private String urlString="";
private InputStream ism;
private URL url;
private URLConnection connection;
private Scanner in;
private int state= 0; public void run(){
download dl1= new download();
System.out.println("================================");
/**
*使用循环为程序分配路径,选定下载的杂志名称后,路径的变化规律可以从filename看出来。
*使用for循环指定杂志名称,年份,期数就可以了。dbname是一年一个库。
**/
//爬取变动部分为828101到830200的URL所指向的文献描述页面
for(int u= h;u<=830200;u++){
try{
if(dl1.getStat()==1){
System.out.println("U的值是不断变化的"+ u+"状态值为"+ dl1.getStat());
u--;
System.out.println("U的值是不断变化的"+ u);
}
if(dl1.getStat()==2){
System.out.println("U的值是不断变化的"+ u+"状态值为"+ dl1.getStat());
u--;
System.out.println("U的值是不断变化的"+ u);
}
//所要下载的文献描述页面的URL
//urlString="http://epub. cnki.net/grid2008/detail.aspx? filename= KJQB200"+ u+"&dbname=CJFD2008";
//读取URL
url= new URL(urlString);
System.out.println("读取url:"+ url);
//以URL创建connection对象
connection= url.openConnection();
//链接URL
connection. connect();
//获得URL指向的网页输入流
ism= connection.getInputStream();
//以设定的编码字符集扫描这个页面
in= new Scanner(ism,charset);
//dl1.setH(u);
for(int i=1;in.hasNextLine();i++){
//一行一行的将扫描的数据保存在pageHtmlCode变量中
pageHtmlCode+= in.nextLine();
}
//计算出保存的HTML文件的字符//串长度
int phc= pageHtmlCode. length();
System.out.println(phc);
/**
* URL过滤,根据CNKI网页数据判断当取得的字符(用* pageHtmlCode变量保存)串长度phc= 95时,
*上述url指向的路径不存在;phc=110时,服务器拒绝下载请求,程序进入5分钟休眠
* 5分钟后重新提交下载请求;phc>1000时,链接有效,并进行下载,CNKI
*返回的有效链接一般都在2.5K以上。
**/
if(phc== 95){
System.out.println("此链接无效,跳过!");
}
if(phc== 110){
System.out.println("服务器拒绝下载,线程休眠300秒!");
dl1.setStat(2);
try{
Thread.sleep(5* 60* 1000);
System.out.println("线程被唤醒!");
}catch(InterruptedException el){
el.printStackTrace();
}
}
if(phc>1000){
System.out.println("有效链接,网页下载中!");
//重命名爬取到的文献描述页面
String filename="科技情报开发与经济"+ u;
//创建文件输出流对象,以实现网页信息资源的保存。存储网页的文件夹及网页名称,“科技情报开发与经济”文件夹必须事先创建好。
FileOutputStream fos= new FileOutputStream("E:\\科技情报开发与经济\\"+ filename+".htm l",true);
//创建OutputStreamWriter对象,并以设定的编码字符集扫描输出流。
OutputStreamWriter osr= new OutputStreamW riter( fos,charset);
//将网页数据写进文件中
osr.write(pageHtmlCode);
System.out.println("下载完毕");
}
pageHtmlCode="";
}catch(IOException e){
System.out.println("503错误!");
try{
System.out.println("线程进入300秒休眠");
dl1.setStat(1);
Thread.sleep(5* 60* 1000);
System.out.println("线程被唤醒!");
}catch(InterruptedException el){
el.printStackTrace();
}
}
}
}
/**
*线程休眠之后避免程序又从h指定的初始值开始下载**/
public void setH(int h){
this.h= h;
}
public int getH(){
return h;
}
//设置下载状态
public void setStat(int state){
this.state= state;
}
//获取状态
public int getStat(){
return state;
}
}
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。











