



Google 机器翻译已经进化到什么程度

绿蚁新醅酒,红泥小火炉。
晚来天欲雪,能饮一杯无?
支起小火炉,放上新醅的米酒。冬夜即将飞大雪,何不坐在火炉旁,与我痛饮一杯?轻轻巧巧的二十字,让平平无奇的雪夜变得有了颜色,变得鲜活灵动。
在地球的另一边的雪夜,Henry Wadsworth Longfellow 这样写道:
Out of the bosom of the Air,
Out of the cloud-folds of her garments shaken,
Over the woodlands brown and bare,
Over the harvest-fields forsaken,
Silent, and soft, and slow
Descends the snow.
从文字的呈现形式、表达含义,到千变万化的读音、精彩绝伦的修辞,每一种语言都有着独特的魅力。这时,如果没有翻译告诉我们另一个半球发生的故事,该是一件多么遗憾的事情。
尤其是现在互联网内容中,英文占到了 50%,而仅有 20%的人口能够看懂英文。一些使用人数众多的语言如汉语、印地语、阿拉伯语等,尽管内容在增加,但比例仍然较小。对于世界上大多数的人来说,互联网上的大部分内容是与他们绝缘的。
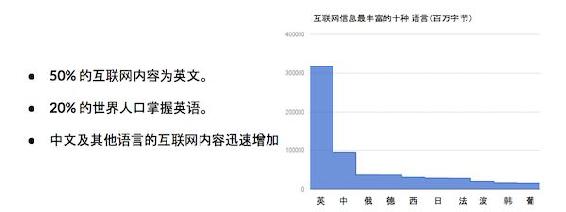
Google 的使命是让所有人都能访问信息。而自动、方便、准确的翻译服务是实现这个使命不可或缺的重要条件。这就是我们在 11 年前推出 Google 翻译的原因。
翻译质量一直是 Google 翻译关注的核心。从 2006 年到现在,我们持续提高翻译质量,并不断推进技术。特别是最近一年多以来,得益于 Google 开发的神经网络翻译,翻译质量得到了巨大的提升。今天我们就跟大家介绍下这项技术。
一、神经网络翻译的翻译质量提高了多少?
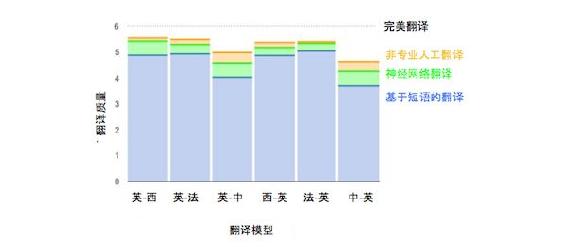
首先,让我们概括看一看神经网络翻译所带来的翻译质量的相对提升。我们对非专业人工翻译、神经网络翻译与基于短语模型的传统翻译结果进行了人工评测。其中 6 分代表完美的翻译结果,而 0 分则代表完全不可理解。可以看到,神经网络翻译的质量要远高于传统机器翻译,甚至有时能取得同非专业人工翻译同等质量的译文。
让我们打一个比方,基于短语的机器翻译模型就好比拼图。通过对短语的排列与组合,试图找出较好的组合方式。然而决定采用哪一块拼图,传统模型并不是根据整幅图的构思,而是根据周围各个图块是否能够契合。因此其决策过程是离散的、局部的。
反观神经网络机器翻译模型,将源语言的句子投射为连续的高维空间张量,并在生成目标语言句子中每一个词的时候,都会考虑整个句子的信息。因此其决策过程是连续的、全局的。以下是一个典型的例子。
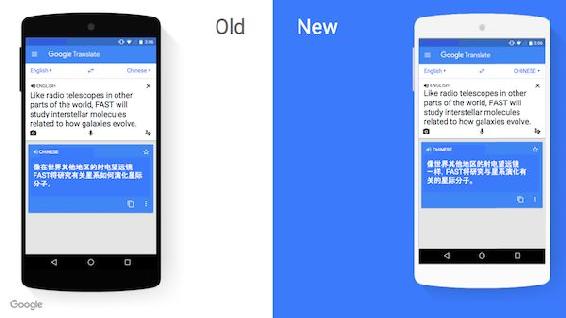
在这个例子中,英语 like 这个词被译成汉语「像……一样」,这个从句的译文为「像世界其他地区的射电望远镜一样」。可以看到「像」和「一样」之间,相差了 12 个字,距离非常远。在传统翻译模型中这样的长程依赖很难解决。同时,英语从句结构会让词序显得比较复杂。若不考虑源语言句子的整句结构,往往翻译结果会非常不自然。
神经网络模型较好地解决了以上两个问题。这一点在最近三年已经得到了科研机构的证明。然而,从实验室的论证,到服务十亿用户的产品,其中需要解决的问题还有很多。
二、多语言神经网络翻译模型的成长之路
在 2015 年 9 月,我们决定投入神经网络翻译模型的研发。面对众多未获得解答的问题,我们为项目定下的模型发布时间是 3 年。然而从 2015 年 9 月获得第一个基于 TensorFlow 的模型开始,到 2016 年 9 月中英模型上线,仅仅过去了 1 年。
截至 2017 年 5 月,我们已经提供了 41 个语言对的翻译,超过 50% 的翻译流量已经由神经网络模型提供,项目的进展大大超出我们的预期。
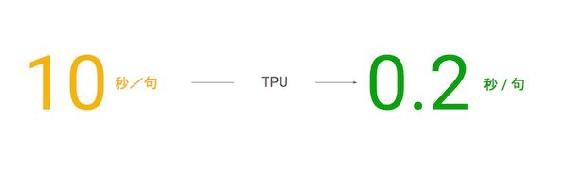
当我们获得第一个模型的时候,每个模型的训练时间需要 2-3 周。一个 20 词的句子,翻译耗时 10 秒。面对可能需要 200 个以上的独立模型,显然这是无法达到上线要求的。Google 对机器学习的全面投入使得我们的弹药库颇为充足。正当我们为提高速度,增大吞吐量努力时,张量处理器的成功研发使得响应速度得以从 10 秒/句提高到 0.2 秒/句。
同时高度优化的代码,通过根据句子长度优化批处理任务,可以最大限度地享受 TPU 带来的效率提升。这使得为数亿用户提供服务成为可能。可以说项目的成功,得益于 Google 在机器学习上的全面布局。
尽管如此,训练与维护数百个单独的模型对我们来说仍然是一个巨大的挑战。因此,我们进一步考虑将多个语言融合到一个多语言模型中去。这样我们不但能够在一次模型训练中就获得多个模型,也使得维护压力大大减轻。同时,我们对多语言模型的研究还获得了许多意想不到的性能提升。
所谓多语言模型,其结构并不复杂。唯一的改变是将需要翻译的目标语言通过语言代码「告诉」神经网络模型。例如,如果训练数据中目标语言是韩语,则只需简单地在源语言句子前加上「2ko」这样的特殊符号。
这一简单的方法被证明性能很好,翻译模型不但能够同时进行英语到日语,英语到韩语的翻译,其翻译质量甚至要好于单独训练的英语到日语及英语到韩语模型。
更为有趣的是,多语言模型甚至可以成功地翻译系统从来没有见过的语言对。例如此处的多语言模型,其中包括英日、英韩、韩英、日英四种语言的训练数据,但是我们并没有日语和韩语之间的直接训练数据。也就是说,系统并没有学习任何日韩、韩日翻译。我们称这种情况为零数据翻译。
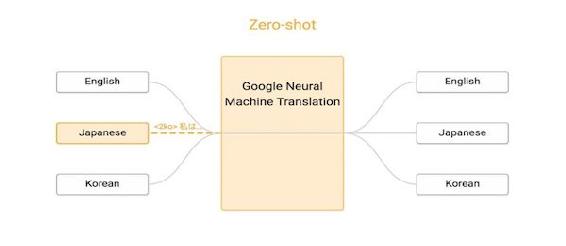
通过多语言模型,我们发现模型能够成功地处理日韩之间的互译。这使得我们无需经过先翻译到英语,再翻译到其他语言作为中转,就能够得到两种非英语语言的翻译。这为未来的统一翻译模型开辟了道路。
如果我们将多语言模型中各个语言的句子在神经网络内部的张量表示可视化,我们会发现,不同语言中意义接近的句子会被投射到相互接近的区域。这表明神经网络对多种语言的语义表示具有一定的普适性。是否这种表示方式就是我们所期待的通用语,这还有待我们进一步研究与论证。
通过张量处理器及多语言模型的帮助,以及 Google 多年在机器翻译数据上的积累,我们在较短的时间内发布了神经网络机器翻译系统,并取得了极大的成功。Google 翻译的使用量在各大市场都得到了很大的提升。同时这一产品的发布也使得机器翻译在过去一年时间内成为业界和学界研究的热点。据统计,在短短一年的时间内,各大研究机构发表了超过两百篇的学术论文。
然而这并不是机器翻译模型的终点。事实上,当我们回顾过去一年,新兴的神经网络模型虽然带来了进步,但是我们对它的理解还很粗浅。我们将进一步改进数字、日期、姓名、习语的翻译以及不常见短句的翻译。而新的模型结构以及训练方法也在不断被挖掘。例如最近 Google 大脑发表的基于注意力的模型。我们认为,这一革命性的新技术只是初露锋芒,还远远没有达到其能力的极限。
除了推进机器翻译技术,我们还推出了更适合移动时代的产品功能,Google 翻译的即时相机翻译功能通过摄像头取词,实现了实景翻译,让世界用你的语言展现在你面前。

生活在世界上的各个角落,不同国家的我们有着不同的文字。而翻译正是通过在文字间架起桥梁,将他国精彩纷呈的文化拱手奉上。希望未来机器翻译的技术能够继续提高,同翻译家们一同建造更多、更结实的桥梁。
结尾附上我们的提问,欢迎大家继续分享好的翻译哦!
哪一句翻译让你觉得语言「妙不可言」?
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。









