



我们开始来分析Hadoop MapReduce的内部的运行机制。用户向Hadoop提交Job(作业),作业在JobTracker对象的控制下执行。Job被分解成为Task(任务),分发到集群中,在TaskTracker的控制下运行。Task包括MapTask和ReduceTask,是MapReduce的Map操作和Reduce操作执行的地方。这中任务分布的方法比较类似于HDFS中NameNode和DataNode的分工,NameNode对应的是JobTracker,DataNode对应的是TaskTracker。JobTracker,TaskTracker和MapReduce的客户端通过RPC通信,具体可以参考HDFS部分的分析。
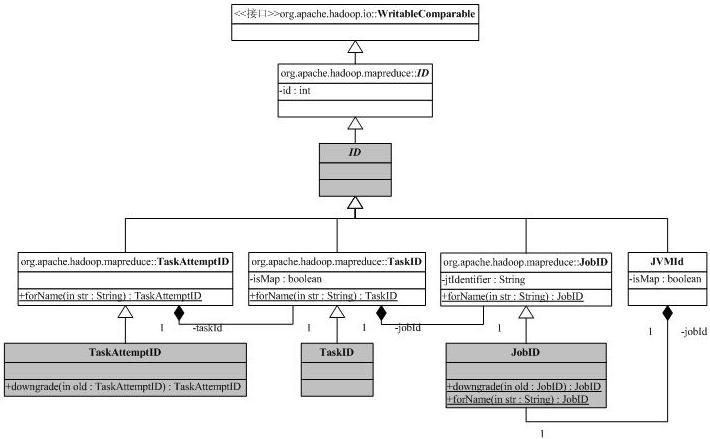
我们先来分析一些辅助类,首先是和ID有关的类,ID的继承树如下:
 源代码分析(IDs类和Context类)%20-%20-%20JavaEye技术网站.mht!http://caibinbupt.javaeye.com/upload/attachment/82912/4feace59-16fc-3512-8ca2-b12880cde606.jpg">
源代码分析(IDs类和Context类)%20-%20-%20JavaEye技术网站.mht!http://caibinbupt.javaeye.com/upload/attachment/82912/4feace59-16fc-3512-8ca2-b12880cde606.jpg">
这张图可以看出现在Hadoop的org.apache.hadoop.mapred向org.apache.hadoop.mapreduce迁移带来的一些问题,其中灰色是标注为@Deprecated的。ID携带一个整型,实现了WritableComparable接口,这表明它可以比较,而且可以被Hadoop的io机制串行化/解串行化(必须实现compareTo/readFields/write方法)。JobID是系统分配给作业的唯一标识符,它的toString结果是job_<jobtrackerID>_<jobNumber>。例子:job_200707121733_0003表明这是jobtracker200707121733(利用jobtracker的开始时间作为ID)的第3号作业。
作业分成任务执行,任务号TaskID包含了它所属的作业ID,同时也有任务ID,同时还保持了这是否是一个Map任务(成员变量isMap)。任务号的字符串表示为task_<jobtrackerID>_<jobNumber>_[m|r]_<taskNumber>,如task_200707121733_0003_m_000005表示作业200707121733_0003的000005号任务,改任务是一个Map任务。
一个任务有可能有多个执行(错误恢复/消除Stragglers等),所以必须区分任务的多个执行,这是通过类TaskAttemptID来完成,它在任务号的基础上添加了尝试号。一个任务尝试号的例子是attempt_200707121733_0003_m_000005_0,它是任务task_200707121733_0003_m_000005的第0号尝试。
JVMId用于管理任务执行过程中的Java虚拟机,我们后面再讨论。
为了使Job和Task工作,Hadoop提供了一系列的上下文,这些上下文保存了Job和Task工作的信息。

处于继承树的最上方是org.apache.hadoop.mapreduce.JobContext,前面我们已经介绍过了,它提供了Job的一些只读属性,两个成员变量,一个保存了JobID,另一个类型为JobConf,JobContext中除了JobID外,其它的信息都保持在JobConf中。它定义了如下配置项:
l mapreduce.inputformat.class:InputFormat的实现
l mapreduce.map.class:Mapper的实现
l mapreduce.combine.class:Reducer的实现
l mapreduce.reduce.class:Reducer的实现
l mapreduce.outputformat.class:OutputFormat的实现
l mapreduce.partitioner.class:Partitioner的实现
同时,它提供方法,使得通过类名,利用Java反射提供的Class.forName方法,获得类对应的Class。org.apache.hadoop.mapred的JobContext对象比org.apache.hadoop.mapreduce.JobContext多了成员变量progress,用于获取进度信息,它类型为JobConf成员job指向mapreduce.JobContext对应的成员,没有添加任何新功能。
JobConf继承自Configuration,保持了MapReduce执行需要的一些配置信息,它管理着46个配置参数,包括上面mapreduce配置项对应的老版本形式,如mapreduce.map.class 对应mapred.mapper.class。这些配置项我们在使用到它们的时候再介绍。
org.apache.hadoop.mapreduce.JobContext的子类Job前面也已经介绍了,后面在讨论系统的动态行为时,再回来看它。
TaskAttemptContext用于任务的执行,它引入了标识任务执行的TaskAttemptID和任务状态status,并提供新的访问接口。org.apache.hadoop.mapred的TaskAttemptContext继承自mapreduce的对应版本,只是增加了记录进度的progress。
TaskInputOutputContext和它的子类都在包org.apache.hadoop.mapreduce中,前面已经分析过了,我们就不再罗嗦。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。








