



二、会计报告的网络披露与呈报——XBRL技术
会计信息对维持正常的市场秩序,促进社会经济的健康发展,具有重大的现实意义和价值。因此,世界各国都几乎无例外地制订专门的会计法律、法规,会计制度、准则等,对企业单位的会计行为进行规范和约束,促使各企业遵循公认的会计原则和程序,生成真实、可靠、可比较的财务信息,同时强制要求企业单位必须定时向政府主管部门、税务机关、市场监管者、证券交易所、银行、投资人或机构、研究机构等众多外部利害相关者披露、呈报以财务报表为核心的财务报告。
(一)会计报告披露与呈报模式的变迁
在传统手工会计时代,财务报告以纸张为存储和传递载体,完全通过手工方式进行编制、传递和交换。信息流同时外化表现为纸张的实物流,这种基于完全手工劳动的财务信息供应链,存在传递效率低下、各实体的作业难以集成、数据重复输入、差错率高等缺点,制约了财务信息的及时性和准确性,信息生产、分配、传播、搜寻成本高,不利于节约社会资源。
随着信息技术,特别是国际互联网Internet的迅速发展和普及,催生了会计信息网络披露模式,即网络会计报告模式。这种新兴模式充分利用现代信息技术,改造财务信息供应链的信息载体、传输介质及流程,有效解决财务信息共享问题,从整体上提升供应链的质量、性能,降低整体运作成本。2000年美国《财富》500强中有94%的企业在互联网上公布其财务信息,中国证监会也要求所有上市公司从1999年起在互联网上公开披露年度财务报告,企业通过互联网发布财务报告已经成为一种必然的发展趋势。
在互联网上,信息的组织形式(数据文件格式)在不到10年的时间内,经历了几代技术的嬗变,即从Adobe可移植文档格式(PDF,Portable Docu— ment Files)→文本文件格式(.TXT)→MS-Office文档格式(.DOC、.XSL等)→超文本标记语言(HTML,Hypertext Markup Language)格式→可延伸标记语言XML(eXtensible Markup Language)标准格式。
(1)Adobe可移植文档格式。Adobe可移植文档格式(PDF)是一种通用文件格式,能够保存任何原文档的所有字体、格式、颜色和图形,而不管创建该文档所使用的应用程序和平台,但是文档的数据、文字必须通过拷贝、粘贴到其他应用程序中才能作进一步的处理,以供分析利用,不能解决财务报告使用时存在的麻烦。
(2)文本文件格式。文本文件格式的文档可以在大部分应用程序中打开使用,但是要想把数据转移到电子表格文件中进一步加工使用,仍然很困难。
(3)MS-Office文档格式。相对前两种格式的文档,MS-Office文档格式(.DOC、.XSL等)在数据的进一步加工使用上要方便得多。特别是XSL格式的文档,可以在不同的财务报表间执行合并、汇总、排序等各种工作。
(4)HTML(Hyper Text Markup Language)超文本标记语言格式。它是Web信息系统利用超文本传输协议(Hypertext Transport Protocol,HTTP)交换信息所使用的一种标记语言,这种语言为网页上的内容提供标记,指引浏览器如何列示页面信息,其制作的信息发布格式就是通常所谓的的网页。超文本原文件中各种元素,如图形、影像、标题、文头、段开始、段内容、段结束、链接以及各种符号都用对应的标记表示。HTML使用称为标签(ta)的指令来标明这些元素要如何放置在文件中,客户机依赖浏览器解释HTML语言,向信息最终用户传递信息。HTML属于国际标准组织(International Standard Organization,ISO)制定的标准通用标记语言(Standard Generalized Markup Language,SGML)的一个子集。SGML是一种通用的文档结构描述标记语言,具有极好的扩展性,在数据分类和索引中非常有用,但是比较复杂;而HTML具有简单易学、灵活通用的特性,使人们发布、检索、交流信息变得非常简单。然而,随着Web资源的日益复杂化、多样化以及信息用户需求的个性化,HTML逐渐显示出其局限性。
HTML是针对信息在浏览器中如何显示而设计的,只能规定信息在网页上显示的格式,而不能描述其含义,也就是说HTML不能将数据内容与显示格式有效地分离开来。例如,HTML可以规定“企业报告”在网页上显示的字体、大小、颜色和粗体等等外观,但却无法定义“企业报告”所表示的具体含义,搜索引擎和应用程序难以根据其语义进行识别。如果在Internet上搜索“企业报告”,将会出现成千上万条信息,由于这种查询模式是针对网页进行全文检索,再找出与搜寻字串相符的文件,所以这些信息可能大部分都不是我们所需要的,有人戏称这种搜寻方式为暴力式搜寻。而除无法进行精确搜寻的缺点外,由于各网页所使用的资料文件格式通常也不一样,所以对搜寻到的HTML资料即使下载后一般也难以再利用,在资料交换上也有所限制,因此HTML主要用于在线内容发布而不是信息交流。
针对上述种种问题,W3C(The World Wide Web Consortium,互联网协会)开始着手制定所谓的XML(eXtensible Markup Language,可延伸标记语言)以弥补HTML的不足。
(5)XML标准化的可延伸标记语言格式。XML是HTML的下一代标记语言,中文称为可延伸标记语言。它对人类提供、使用与交换数据方面带来了革命性的创新。XML是一种自我描述的、可扩展的、标准化的交换数据方法,也是SGML的一个简化子集。XML结合了SGML的丰富功能与HTML的易用性,克服了SGML过于复杂、开发成本高,不适合网络日常应用的缺陷;同时又较好地解决了HTML无法表达数据内容的问题,XML可以做到将内容(data)与样式(style)分开,它不仅像HTML一样告知浏览器如何显示文件与图形,并且还具有提供数据之间关系的能力。而且,XML是可扩展的,允许使用者依其需求自由针对资料定义标签,每个产业或学术研究领域可以自行定义其所通用的标签组,大家再共同遵循使用这套标准,透过XML统一文件的结构、命名、语意、处理逻辑以及异质信息及文件格式之转换,能从页面上直接检索相关信息并传送给其他应用软件或者将它保存在数据库中,达到网路资讯有效存取、处理、交换、转换的功能。例如“account”这个字,可能指银行的账户,也可能是会计上应收应付的账款,透过XML,银行业以及会计界就可以依自己的需求定义标签加以区分。事实上,各行各业都可以应用XML,因此不管对科学、化学、医学、工业以及商业均产生很大的影响。
XBRL(eXtensible Business Reporting Language)则是与商业报告有关,以XML为基础所发展出来的语言,它是专门为规范网路财务资讯的披露与呈报而产生的资料交换标准。
下面,我们来较详细地介绍一下XBRL的基本内容。
(二)基于XBRL的会计报告的网络披露与呈报
1.XBRL的开发历程
XML在会计行业的应用,使XML扩展和升级成为XBRL(eXtensible Business Report Language)。开始时,以XML为基础的财务报表框架标准被命名为XFRML(eXtensible Financial Report Markup Language,“可扩展财务报告标示语言”),后来发现XFRML不仅仅局限于财务报告方面的应用,它已经可以满足商业社会信息处理的需要,于是更名为XBRL。XBRL是一种可免费获取的用于财务报告的电子语言,其目的是要提供一个以XML为基础的全球企业资讯供应链之架构,以方便使用者去取得、交换和分析相关的信息。XBRL为财务机构准备、公布各种格式的财务报表、可靠地抽取及自动交换公开发行公司的财务报表及其他信息提供标准化方法。
XBRL的研发历史可追溯至1998年。1998年4月,美国注册会计师霍夫曼(Hoffman)等对用于电子财务报告的XML技术进行了研究后认为,XML还不能完全符合企业报告的非凡需求,XML的电脑指令表必须扩展到包括更明确的企业报告描述,不仅能识别每一个数据,而且还能告诉计算机应该如何处理、如何与其他标记的信息连接、应该在哪里连接这些数据以及与企业报告相连的数据的构成要素,根据该设想,他们开发了使用XML的财务报表的原型与审计时间表,并在1998年7月就财务报告中使用XML技术的潜力向AICPA高科技特派组主席进行了汇报。1998年9月AICPA高科技工作组提出了使用XML技术的财务报告原型创建的“产品描述”(Product Description),并于1998年10月得到了AICPA的资助,以创建使用XML的财务报告原型。1999年7月,AICPA与多家跨国公司合作成立了XBRL指导委员会,之后随着越来越多国家和地区开展XBRL的研究和实践,又成立了XBRL国际组织(XBRL International)。2000年7月,XBRL的研制开始取得初步成果,XBRL指导委员会发布了第一份XBRL财务报表规范XBRLV1.0规格书和XBRL分类标准(Taxonomy),该XBRL分类标准是根据美国制造业和商业适用的公认会计原则制定的。2001年12月,XBRL指导委员会又正式颁布了XBRLV2.0规格书,与V1.0相比,V2.0提供更加标准的结构,能够从特定的行业,如工商业中将会计的核心概念分离出来,其次,它增强了分享其他团体发展的分类标准的能力。而最新的版本是2003年4月23日发布的V2.1,XBRL V2.1又对前两个版本进行了多方面的提升,如增加了Formula Link Bases并扩展了US GAAP和IAS GAAP分类信息,并在许多技术环节上做了改进。XBRL技术的成功开发,为XBRL在全球范围推广奠定了基础,目前这项技术仍在不断的推广与完善中。
在XBRL的发展过程中,XBRL国际组织——XBRL国际联合会(XBRL International)发挥了重要作用。该组织1999年 10月13日在美国成立,是一个非营利的全球联盟组织,其目标是建立全球统一的XBRL分类标准、推动XBRL的国际化。具体说来,XBRL国际联合会的主要目标有以下六个方面:
——降低信息交换成本,提高财务信息的可获得性。
——通过互联网提供具时效性的信息,提高信息的相关性。
——可自动交换并摘录财务信息而不受个别公司软件和信息系统的限制。
——可以减少为了不同格式需求的资料而重复输入的问题。
——解决由互联网上获取的HTML格式的财务信息不能直接用作分析、比较的困难。
——为投资者或分析者使用财务信息提供方便。
截至目前,XBRL国际组织已经召开了18次国际会议,全球范围内的成员已有550多个,包括中国在内的25个国家和组织已经正式建立XBRL地区组织,许多国家也开始积极参与XBRL的研究和开发。XBRL国际联合会成员包括注册会计师协会、银行、交易所、IT厂商、信息商等,如:德意志银行,联邦储蓄保险公司,富士,日立,通用电气,IBM,微软,摩根斯坦利,PeopleSoft,普华永道,路透社,SAP和其他公司,代表了商业报告供应链的所有成员。该组织的成员都已经承诺在一致同意的基础上应用数据录入交换格式以利于共享,而且这些成员也承诺将协定内容具体应用到他们的产品和服务中。
XBRL国际联合会建立全球统一的XBRL分类标准,推动XBRL国际化的工作策略是首先在各国家内部,依据不同行业的会计准则实现同业分类标准的统一(经XBRL国际组织的认证),然后逐步寻求实现国际化同业分类标准的全面统一。各国XBRL组织负责建立符合本国会计准则的XBRL分类标准,而XBRL国际组织负责制定全球统一标准,XBRL技术标准由XBRL国际组织以及各国的XBRL组织协同推进。目前这一工作已经取得了巨大的进展:自2001年XBRL国际组织颁布了总分类账XBRL以及以美国GAAP为基础的明细分类标准以来,许多国家如美国、英国、德国、加拿大、澳大利亚、日本、新加坡等以及国际会计准则委员会都纷纷地颁布了以各自GAAP为基础的XBRL明细分类标准。截至2008年6月,已有13个国家和地区的财务报告分类标准分别获得了XBRL国际组织的认证,成为这些国家和地区正式运用的XBRL财务报告标准。目前,中国、澳大利亚、比利时、加拿大、丹麦、法国、德国、印度、以色列、日本、韩国、荷兰、新加坡、西班牙、瑞典、泰国、英国和美国18个国家已经在有关财务报告或者其他报告项目中自愿或强制性地使用了XBRL。可以预计,XBRL必将会逐渐发展成为网际网路上所有企业报告的国际通用商业语言。
目前,XBRL在中国的研究和应用也取得了令人瞩目的成就。早在2000年初,财政部就注意到XBRL对会计准则应用和财务报告编报的革命性影响,主动邀请国际会计准则委员会及有关XBRL专家来华交流。之后,财政部积极引导理论界开展XBRL相关研究,在中国会计学会专门成立了会计信息化专业委员会,并从2002年开始,就XBRL在我国的建设与应用问题形成了一批有价值的研究成果;从2003年起,财政部和审计署、上海市财政局基于XBRL原理研究制定会计核算软件技术标准,并于2004年共同推出国家标准《信息技术——会计核算软件数据接口》(GB/T19581—2004)。在这一过程中,中国证监会及上海、深圳两个证券交易所为了XBRL的推广应用做了大量卓有成效的工作。目前,我国所有上市公司已要求按照XBRL提供财务报告,这在世界上处于较领先地位,推动我国XBRL应用走在了其他许多国家的前列。与此同时,有关监管部门、科研院校等也开展了XBRL相关研究。特别值得提到的是,经过多方的不懈努力,XBRL中国地区组织已于2008年11月12日正式成立。这一组织的成立,标志着我国XBRL的研究和应用工作已经全面融入国际化的大家庭。
2.XBRL的技术原理
XBRL 源于 XML,要深入理解 XBRL,就需要首先了解 XML,限于篇幅这里不再对XML技术做更多的介绍,我们仅基于XML简要介绍一下XBRL的技术原理。
XBRL的信息模型主要由四部分组成:规格说明书(Specifications)、分类标准(Taxonomy)、实例文档(Instance Documents)和样式表(Style Sheets)。其中XBRL分类标准(Taxonomy)是XBRL信息模型的关键技术核心,因此也将是我们侧重要介绍的内容。
(1)XBRL规格说明书(Specifications)
XBRL规格说明书主要用于描述XBRL文件的结构,详细规定XBRL分类标准和XBRL实例文档的语法和语义。规格说明书从技术角度解释了“XBRL是什么”,以及“XBRL怎样工作”。目前最新的XBRL规范是XBRL国际组织2003年4月23日颁布的XBRL Specification2.1版。
(2)XBRL分类标准(Taxonomy)
①Taxonomy的直观认识
我们首先来直观地认识一下这一概念。在英文字典中,Taxonomy的解释通常是“分类法、分类学”或者是“词汇、词典”的意思。在XBRL中,Taxonomy主要是用来定义制作财务报表时所需用到的各项报表元素,在这个意义上,我们可以把Taxonomy理解成“词典”,同时它所定义的这些要素相互间存在着数据层次构造,每一要素都是依据不同的层次标准进行分类的,所以Taxonomy也具有“分类法”的含义。
我们先来看下面一些貌似杂乱无章的财务数据:
固定资产累计折旧 456,156
固定资产 637,784
无形固定资产 999,318
长期投资 5,485,816
Earned Surplus 6,695,864
非流动资产 7,122,919
Capital Stock 7,257,059
长期负债 7,694,248
未分配利润 11,564,916
其他流动资产 12,927,756
流动负债 20,287,764
所以者权益合计 25,517,839
负债合计 27,982,012
Cash and Deposits 33,449,175
流动资产 46,376,931
Assets 53,499,851
负债与所有者权益合计 53,499,851
这些数据实际上是一张财务数据表中的相关财务数据,通常只有财会专业人士也许才能读懂这些数据的含义,并能很轻松将这些杂乱的数据按照资产负债表的基本等式“资产=负债+所有者权益”重新编排,将英文项目名称转换成合适的中文项目名称,并对于固定资产累计折旧也适当在附注中加以备注,以致其迅速形成以下较规范的资产负债表。
但是,同样的上述工作对于非财会专业的外行人来说,恐怕就有点勉为其难了。而实际上,这样的工作对于计算机来说也是一样的,如果没有能够让其读得懂的“词典”规则,那么它也是什么也做不了,而这就是XBRL Taxonomy的作用。
资产负债表
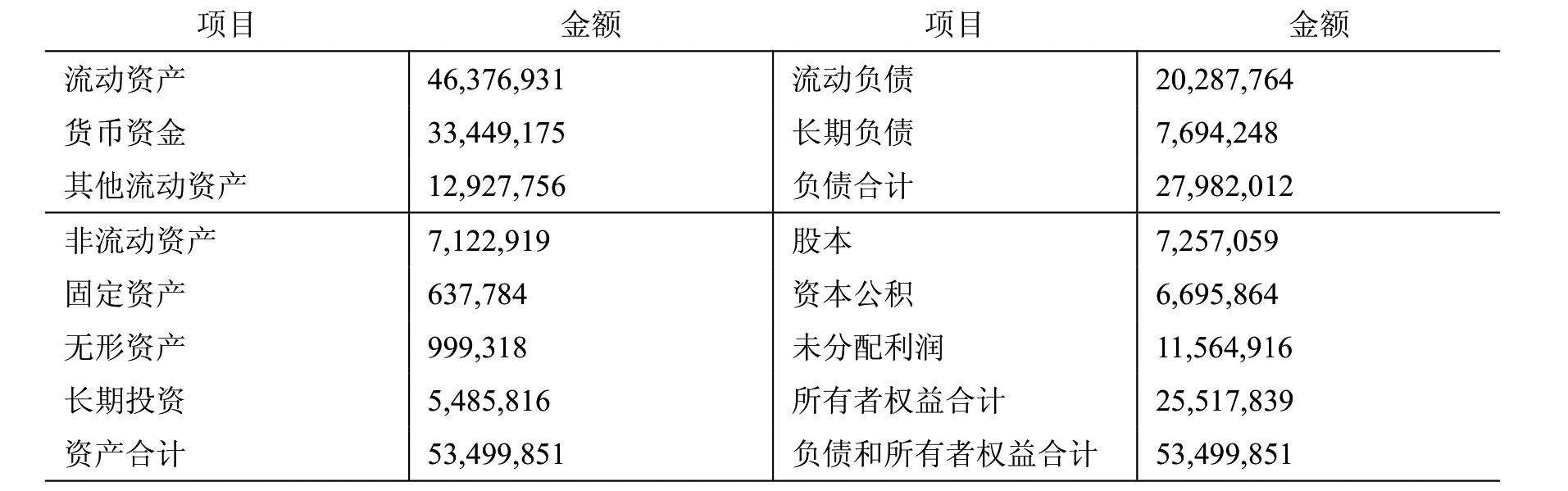
#注:固定资产累计折旧 456,156
Taxonomy首先要依据一定的会计准则,利用Xml Schema等技术,对财务报表中的各项元素进行定义,即将数据分别粘附不同的标签,同时也要对各个元素在报表中的名称、位置、形式、属性及其之间的关系进行定义,XBRL2.0以上版本还使用了XLink以实现内容与附注之间的关联,或者内容与表达形式之间的关联,另外还要反映出制作财务报表所依据的会计准则。这个过程就是所谓的制作财务数据“词典”,而由这些标签汇总称为XBRL的分类标准(Taxonomy)。在老的XBRL技术规格中曾经使用过DTD,目前的2.0和2.1版中都主要使用Xml Schema技术。计算机根据这个制定好的Taxonomy就能理解财务数据的含义,然后根据用户的要求显示或收集相关的财务数据。XBRL分类标准(Taxonomy)相当于是一个行业商业信息交换的“词典”,也是其编制财务报告和交换财务数据的标准。基于这一标准,反映企业交易和经营情况的会计信息就可以以一种标准的形式归类并生成报告。
比如一家公司要想利用XBRL公开自己的财务报表,那么就可以使用分类标准预先规定好的标签,将自己公司的财务数据放在相应的标签里,这些内容就组成了实例文档。这些看似复杂的内容再经由XSLT和CSS转换,就可以在浏览器中得到通常的财务报表。
②Taxonomy的技术组成
有了上面的直观认识,下面我们就来较深入地介绍XBRL分类标准(Taxonomy)的技术原理。前面说过,XBRL分类标准是XBRL 信息模型的技术核心,而每一个XBRL分类标准又是基于一个XBRL 实例(XBRL Instance)实施的。XBRL实例中封装了具体的商业事实,其中最基本的单位是事实(Facts)。例如,最近一个季度的销售额(“Sales In The Most Recent Quarter”)就是一个事实。没有复杂信息结构的简单事实叫条目(Item)。为了表达较复杂的信息单元,可以把一组相关联的事实放到一起,用相对复杂的结构比如元组(Tuple)等来表示。元组中既可以包含条目,也可以包含其他的元组。条目对应于商业概念。而这些商业概念、具体事实的业务含义、定义描述,应该遵守怎样的语言规范,以及他们的形式、属性如何,则是由分类标准(Taxonomy)来定义的。
一个XBRL分类标准是由多个文件组成的文件组。主要文件包括一个Taxonomy Schema(.xsd)文件和五个linkbase数据库链接文件(即计算、定义、标签、展示和引用)。分类文件声明了一系列要素,包括要素命名、ID属性、要素类型等内容,描述了要素之间的定义关系。每一个条目(Item)的数据值都对应一个标签,这种方式使每一个条目的数据都以“元”数据的形式存在,以便于交互与计算。如商品采购表单实例中的系列商品,每一商品的品名、数量、金额等等,都有一个唯一标签标记(而不同于关系型数据表或者EXCLE纵列表的格式,通过字段项和数据行确定“值”)。多个条目组成一个元组,如“商品采购单”或者“资产负债表”等,都可以视为由多个条目组成的一个元组。由于每一个条目都可以单独定义属性,使得数据表单中输入和显示的每一个“元”数据都可以参与数据统计分析,因此也成为分类标准报告的原始数据,比如“现金与市场证券”(Cash and Marketable Securities)与“现金与短期投资”(Cash and Short Term Investment)中都包括有现金这一基本成分,那么XBRL格式可对现金加以标记以便根据需求抽取,当若仅仅需要“现金”的数量时,只要检索现金项目,而若需“现金和短期投资”的数量,则可选择组合。
除条目外,XBRL实例中的所有元组、事实也要在分类标准中定义“名称(name)”和“数据类型(type)”等。这些数据类型包括有表示日期的xbrli:dateTimeItemType、表示字符串的xbrli:stringItemType、表示金额的xbrli:moneytaryItemType,还有decimalItemType、shareItemType、uriItemType等等。原则上,所有的元素都应该包括在xbrli:item或者xbrli:tuple这两个可替代组(substitution Group)中,换句话说,这两个组中所没有的元素原则上都不能写进实例文档(Instance Documents)。
在Taxonomy Schema(.xsd)文件中还定义了链接元素link:linkbaseRef(含计算、定义、标签、展示和引用等五种),其属性分别定义了各linkbase的作用和链接的数据库文件。
标签链接(label links)数据库文件和引用链接(reference links)数据库文件把商业概念(business concepts)和元数据(metadata)联系起来,确定了项目在财务报告中实际显示的名称,举例来说:我们知道一个文本串(text strings)可以用来标记(label)或文档化(document)一个报表中的概念,而标签链接(label links)则可以把这个文本串和相应的概念联系起来,比如,可以用标签链接把文本串“最近一季度总收入”(Revenues in Most Recent Quarter)和分类中定义的“revenueMRQ”条目联系起来。单个儿的商业概念可以用多个标签多种语言来标记。具体XBRL实例的创建者(author)来决定该实例各个标签的取舍。
图2-7中阐明了定义一个关联链接(label link)关联一个商业概念和标签所要做的三件事:用label element标记商业概念,用loc element 为该概念定义一个定位器(locator),用一个labelArc element 定义一个“弧”(arc),把此商业概念联到指定的label上。引用链接也是通过类似的方式把引用链接到商业领域(domain)的权威文献上去,所使用的机制类似于标签链接:定义一个引用链接和一个定位商业概念及相关文档引用的定位器,最后再建一个referenceArc element 将前面定义的定位器和引用关联起来。

图2-7 定义一个关联链接(label link)关联一个商业概念和标签
标签型链接和引用型链接是用来关联商业概念和元数据的。其他三种类型的链接恰恰与之相反,是用来建立不同商业概念之间的关联的。例如:计算数据库链接文件就是用来定义相关商业概念的计算关系的。举个例子:“税后利润”(“profitAfterTax”)的概念是由“税前利润”(“profiteforeTax”)的概念减去“所得税”(“taxPaid”)的概念得到的。
profitAfterTax=weight(1)×profitBeforeTax+weight(-1)×taxPaid
图2-8是示例怎样将这三个商业概念联系起来。

图2-8 在“税后利润”与“税前利润”和“所得税”概念之间建立关联
定义数据库链接文件从概念角度描述了几种商业概念间的关系,如泛型和具化关系(Generalization-Specialization Relationships),如“postalCode”是“zipCode”的泛化等。展示数据库链接(presentation links)文件,正如名字的含义一样,从展示的角度(presentation perspective)定义不同商业概念之间的关系,例如,在展示报表中,“销售”sales和“打印机销售”printerSales应该显示为父子关系。
经过以上过程,实例中的每一个数据都通过“语境标签、计算关系、表现形式、规则定义、参考关系”进行了约束和规范。由于依据XBRL标准所定义的表单数据要细化到每一个条目、元组、事实等元素项目,因此定义过程所涉及的技术细节会较为繁琐。
每个XBRL实例通过引用一个模式(Schema)来关联到对应的分类(Taxonomy)上去,而每一个模式又可以引用其他的模式。为验证一个XBRL实例的语法需要的所有模式(Schema)构成的集合(Collection)组成该实例的可发现分类集(Discoverable Taxonomy Set(DTS))的一部分。所有这些schemas和linkbases合起来构成所谓的DTS,这样我们便能够描述整个报表中的商业概念。
在上述整个定义过程结束后,要由XBRL处理器(XBRL processors)来对语法定义进行验证。XBRL处理器不仅要按分类模式(Taxonomy Schemas)来校验实例文档(Instance Documents)的语法,也要按分类链接集(Taxonomy Linkbases)来验证实例的语义。当对实例文档进行处理时,处理器要能根据实例的分类提取出应用所需的元数据。这个过程和XML模式(Schema)验证(Validate)以生成PSVI类似。XBRL验证应当拿分类(Taxonomy)来验证实例并将验证过程所得的元数据(Metadata)送给应用(Application),比如处理器应能在报表实例中检测到一个条目(Item)的元数据label。除了验证之外,XBRL工具(XBRL tools)还包括:分类编辑器(Taxonomy Editors)、XBRL实例生成(XBRL instance creation)、XBRL储备器(XBRL repositories)及查询报告引擎(query and reporting engines)等等。
③Taxonomy的数据模型
Taxonomy体系的复杂性来源于现实中会计准则和会计实务的复杂性。比如“有价证券”这个财务数据元素,按照会计准则可以分成不同类型,同时各个国家会计准则对该项目的分类也不一样。因此考虑到不同的国家有不同的会计准则,制定Taxonomy必须要基于一定的数据模型,以免在数据构造上产生前后矛盾。XBRL技术标准的数据开发模型是基于数学图论的理论。通过数学图形将不同的要素(vertex或node)和表示要素间的相互作用的线(arc或edge)模型化,在此基础上完成XBRL技术标准。关于这一数据模型,我们这里不再展开介绍。
④Taxonomy文件组的命名规则
我们以资产负债表为例,一个基本的资产负债表的Taxonomy的文件组可以用以下名称来表示:
Taxonomy Schema cn-bs-2008-12-31.xsd
计算Linkbase cn-bs-2008-12-31_caluculation.xml
定义Linkbase cn-bs-2008-12-31_definition.xml
标签Linkbase cn-bs-2008-12-31_label.xml
表示Linkbase cn-bs-2008-12-31_presentation.xml
参考Linkbase cn-bs-2008-12-31_reference.xml
文件中的2008-12-31是指假设按照2008年12月31日的财务报表编制准则来制定的Taxonomy。每个Taxonomy的文件名称都经常使用具有特定含义的名称空间(name space)前缀,除了通过日期来表示编制依据的会计准则版本外,还可以表示各种不同用途的Taxonomy。例如我们可以将不同的Taxonomy种类定义成以下不同的名称空间前缀。
通用企业财务报告 cn-gcd
基本财务报表
资产负债表 cn-bs
利润表 cn-pl
现金流量表 cn-cf
利润分配表 cn-sr
合并资产负债表 cn-cbs
合并利润表 cn-cpl
合并现金流量表 cn-ccf
合并利润分配表 cn-csr
用途分类
股份公司财务报表 cn-sa
中期财务报表 cn-sh
纳税财务报表 cn-ta
行业分类
一般企业 cn-XX-ci
建筑业 cn-XX-cn
金融业 cn-XX-fi
物流业 cn-XX-tr
医院(等) cn-XX-hs
审计报告 cn-ar
个别企业 sh600000(*1)
sz900000(*2)
注:*1、*2分别代表在上交所和深交所上市的公司。
(3)XBRL实例文档(Instance Documents)
分类标准定义好后,各个企业就可以依据标准将本企业的财务数据XBRL化(当然应当是执行与分类标准所依据的会计准则背景相同的企业)。实例文档是根据所使用的分类标准中的概念进行标记的一套数据元素的集合,主要包含财务报告中的标签和数据。XBRL根据财务报告中标签与会计业务数据的对应,利用应用程序将自动从会计系统的业务数据库中提取数据,生成实例文档。当然这些实例文档的基础数据有时也可以按照现有的财务报表模型以手工的方式输入完成。
微软公司是最早使用XBRL分类标准披露自己财务报表的公司,其XBRL财务报表的源文件与分类标准类似,只是附加上了微软公司的相关信息,比如报表结算日期、公司的详细情况以及财务报表的各项实际金额。
(4)样式表(Style Sheets)
实例文档是数据和解释性标记构成的集合,但却不是以“用户友好”的方式加以组织的,XBRL并不是“所见即所得”,其格式不易直接阅读,它看起来可能要与财务报表相去甚远。它只是为了实现数据在系统间传递并保证其可靠性和一致性而设计的,因此必须要对实例文档内容按财务报告的发布格式进行编排才能以人们所熟悉的报告格式显示。样式表即是用于定义财务报告发布时的显示项目和格式,而实例文档则为样式表(财务报表)的数据来源。为了开发出有用的财务报表,样式表可以在实例文档的数据中添加一些必要的表示性元素,这样产生的结果看上去就像一份财务报表了。当然,这份报告不一定要打印出来,也可以以HTML或其他格式呈现。
需要说明的是,基于XBRL技术的实例文档,在实际中并不一定非要最终以财务报表的格式打印输出后才能被应用。该文件可以直接发布、转换成XML文件、转换为HTML或PDF文件,或是用于合并或数据转移。如果只是为了财务报告的目的,这时候可以在网站上发布一个实例文档,这份文档可能是按照国际会计准则(IAS)或其他准则的分类标准而编制的。分析师或其他信息使用者仅需基于这些数据运行他们的分析程序,通过采集为数众多网站上的其他公司的数据并将这些信息整合于一份报告来准备他们的可比性报告。通过XBRL,这个过程将是自动的,并可定期从多种来源中检索数据资料。XBRL的应用绕过了财务报告的打印部分,并使信息源更加具有可靠性和完整性。而随着使用互联网进行披露的企业数量不断增长,最终人们将无需再求助于打印的财务报告。
3.XBRL的运作
由前面分析看到,XBRL是一个添加标记的计算机程序,它要求被计算机处理的每则信息都要有一个可识别的代码或标记相对应。不仅如此,XBRL还具有良好的可扩展(eXtensible)性,即完全可实现定制(Customizable)。如果XBRL程序没有包括符合企业需求的标记,企业可以开发特殊标记并添加到程序中。XBRL最终可为具有特殊性的不同领域及不同行业设计出不同版本,但所有版本都基于同样的XML框架。但是,成功利用XBRL总要符合三个必要的条件:有一套适用于所有公司的说明书;有一套符合说明书的应用程序,用以编制XML标记的财务报表;有一套可以移交信息给特殊及各种格式的样式单(Style Sheet)。
由于XBRL是一个基于XML的跨平台的数据传输标准,只要用户的浏览器支持XML,就可以像浏览HTML格式的网页一样,浏览和下载XBRL格式的财务报告或把数据导入电子表格运用程序进行计算和分析,XBRL能自动、清晰地识别、转换信息使用者选择的包括数字和文字的所有企业信息,当前的浏览器都支持XBRL。在大多数情况下,会计软件将自动嵌入这些标记,即使会计软件缺乏XBRL特性,也可运用一个免费的添加程序或定制的标记工具软件添加这些标记。这些标记不因数据移动或更改而消失,无论浏览器或应用软件怎样格式化或重新安排这些信息,这些标记仍粘附在数据后。典型的标记包括财务标记,例如资产、流动资产和应收账款;还包括公司名称、注册地、部门、年份等信息。特定的XBRL解析软件将标记过的数据与分类标准一一对应,之后该映射可以被保存在电子数据表中,而其中的数据则能够在试算表中显示出来。用于数据的标记与其他用于定义计算机视觉特征的格式标记一起内嵌在信息中,当屏幕上显示或打印输出企业数据时,用户实际上看不见这些标记。在会计系统中将分类标准映射到数据文件,将使得能定期自动产生财务报表,或至少在理论上能实时产生。
目前,一些软件开发商,如SAP、GREAT PLAINS、 NAVISION、ORACLE和ACCPAC等,已经将生成XBRL实例文档的功能嵌入其软件产品中,可以使用样式表和实例文档准备财务报表,或者将数据直接导入预算和分析工具中。如果企业所采用的软件不支持XBRL,也可以通过自行研制或使用第三方软件,生成XBRL财务报告,如Excel 2003等。
4.XBRL的技术特点
基于以上分析,我们下面对XBRL的一些主要技术特点进行归纳:
(1)无许可证限制
XBRL具有良好的开放式技术构架,可以使任何财务信息链上的人都能免费、自由地在不同的软件平台上获得、交换并分析财务信息。
(2)跨平台使用
由于XML文件可以跨平台使用,使得源于XML的XBRL技术天生就具有跨平台的优势。在不同的操作系统下,如Windows、Unix和Linux等,XBRL文件无需修改就可以直接使用。在不同的应用软件中,即使所用的数据库不同,只要转换成XBRL格式,也可以实现数据的交换。因而,通过XBRL信息可以在不同的操作系统、数据库和应用软件之间进行传输和交换,XBRL是一种互联网上企业报告的通用语言。
(3)多种格式输出(供方)
XBRL分类标准除了由XBRL国际组织定义的应用于总分类账层面的基本分类标准外,各国可根据自己国家的GAAP制定相应的、分行业的分类标准,企业依照分类标准再制定自己的实例文档。因为分类是通过实例文档来申明的,实例文档本身采用XML格式而支持继承,所以实例文档可以是扩展了的分类文档,并在自己的XBRL实例文档中得到引用,形成扩展后的分类标签。因此,企业对发生的每一业务事件进行标记后,可以根据不同的GAAP实例文档,生成不同GAAP下的财务报告,也可以实现不同GAAP下的财务报告的编制、转换与合并,无需按提供对象不同而编制不同格式的财务报表。
此外,在XBRL国际组织制定的XBRL体系中,公司的内部报表被称为XBRL GL(财务记账),其分类标准(Taxonomy)包含会计科目、总分类账、明细分类账、试算表、账簿、交易记录、财务和非财务信息等等。公司的外部报表被称为XBRL FR(财务报告)。使用XBRL GL后,公司在每一个事件发生之时加上相应的标识包括记录每一笔交易的时间、相关人员、涉及的单据、供应商、销售商等数据信息,并进行汇总,然后将汇总的会计记录联结至XBRL FR,就能精确、迅速完成财务报表的编制工作,除此之外附注和其他财务报告中存在相互勾稽关系的数量部分也基本能实现自动编制,这将大大提高报表编制的效率。
所以,对同一份XBR实例文档,采用不同的样式表,可以生成多种企业报告。财务数据只需键入一次, XBRL对不同用途的财务报告无须进行多次格式化,如打印的财务报表,公司网站所需的HTML文档,原始的XML文档,或诸如信用报告与贷款文件等其他特殊报告格式。XBRL文档不仅降低了公司编制与发布财务报告的成本,降低了重新键入错误的风险,而且还提高了投资者或分析师获得信息的容易程度。
(4)能够适应变化的会计制度和报表要求
因为XBRL将财务数据进行细分,变动的格式只是变动在一张报表内需要集成的财务指标,不同格式的报表之间,在相同的财务指标上仍然具有可比性。因此通过底层“元”数据的重新组合,使财务报表能适应各种变化的会计制度和报表格式要求。另外,XBRL还可以设置许多要素之间的对应关系,例如“销售收入”术语在英国使用“Turnover”,而在美国则使用“Sales”,XBRL将两者等同起来,那么XBRL技术还可以支持在不同语体之间实现报表格式和信息之间的相互切换。例如,在XBRL环境下,跨国集团只需输入一种格式的基本财务数据,通过点击按钮就能马上产生另一种格式的财务报表。如IBM公司的德国和日本股东通过点击鼠标,IBM最近的年报和账目就分别以德国和日本的格式呈现出来,这将大大减轻IBM公司编制多套报表的任务。当然对于经常需要提供几种版本财务报表的中小企业而言也将受益匪浅。
(5)信息搜索快速、准确(需方)
XBRL使用标签描述数据的含义,在进行数据搜索时,不是像HTML那样根据字面内容进行搜索,而是根据标签的语义进行定位,这样搜索引擎能够快速、准确地找到用户所需的特定信息。同时由于XBRL采用标签来标记数据,可以通过应用程序对搜索结果中的数据进行汇总,其效率将远远高于目前互联网上PDF、WORD和HTML等文件格式。
另外,有标签标记的XBRL格式文件的所有数据中,相关信息之间互相连接,如固定资产与资产负债表及折旧相连,如果信息用户在互联网上搜索有关通用汽车公司(CM)的固定资产信息,那么支持XBRL技术的搜索工具便能迅速定向检索用户所需的目标数据,而且如果用户需要收集多个公司的固定资产数据以比较公司的经营情况,则只需对搜索工具加以调整就可以实现这一目标,并将有关信息轻易导入电子表格以便进一步分析。
(6)信息具有良好的可比性
由于XBRL保证了数据之间充分的线索关系,因此在XBRL 技术支持下,企业信息可以实现良好的内外、纵横可比性。如基于XBRL.GL和XBRL.FR的对接,XBRL可以通过分类、汇总、检索、传递和列示自动生成财务报表(可称为XBRL的向上综合功能),同时还可以沿着原来的路径向下挖掘考察直至最底层的数据源甚至对数据支持的相关权威文献(可称为XBRL 的“下钻”功能),如在阅读企业资产负债表时,如果想了解固定资产的详细信息,可以进一步通过标签追踪固定资产的总账、明细账,直至记账凭证。不仅如此,使用XBRL标记的财务报表,也为数据其他更广泛的比较分析提供了可能性,如财务数据可以跨期间、跨年份分析,也可以跨越多报表、多公司、多行业乃至多国家的进行比较分析。例如借助上海证券交易所推行的XBRL Pilot Project,信息使用者能够按需获取上证180成分股指中上市公司最近4年的财务数据和实例文档。深圳证券交易所不仅提供资产负债表、利润及利润分配表、现金流量表和股本结构表等的原始数据,而且还提供了l1个比率类指标近5年年报历史数据的对比,并能用折线图或柱状图等图形化方式直观揭示公司财务状况走势,极大强化了使用者进行更广泛财务分析的能力以及根据决策模型对信息再分析与再利用的能力。
(7)信息具有良好的可读性与维护性
由于XBRL的文件是以ASCII码存档的,使用支持ASCII码的简单文书处理器就可以轻易读取或修改,因此使信息资料具有良好的可读性与维护性,非常适合于需长期保存的文献资料。
但是需要强调的是,XBRL并不意味着其自身能对公众释放信息,而是确保相关主体能够读取确已存在的数据的能力。XBRL是在不影响现行会计原则的情况下去做网际网路财务报表的改良,它是一种技术上的改变,而不是基本会计衡量原则的改变。
5.XBRL的应用领域
XBRL不仅提高了财务报告发布的效率,而且对其他领域也产生了深远的影响,财务信息供应链上的所有使用者都从中受益,包括企业、证券和金融机构、政府部门和投资者等。
(1)企业。XBRL利用模板保存企业报告的格式和标签,企业编制财务报告时,通过应用程序可以直接从会计业务数据库中提取数据,保证了数据的准确性,提高了报表编制的效率。同时XBRL还可以用于企业内部报表和分析报告的编制。利用XBRL的跨平台和开放性,无论企业各部门采用何种管理系统,无需添加硬件设施,就可以实现部门之间信息的共享。
(2)证券管理机构。按照我国证监会的要求,上市公司必须要在指定的媒体如报纸、网站和证券交易所公开发布公司相关的公告事项。如果上市公司采用XBRL格式公告自己的信息,不仅便于阅读,而且还可以通过软件来进行分析和汇总,企业报告中的异常数据更容易被发现。
(3)金融机构。金融机构在研究财务动向和风险分析时也可以有效地利用XBRL,通过XBRL可以发送复杂的数据查询请求,对信贷申请进行实时地可比性分析,有效地评估公司的风险及等级,从而降低风险并且提高贷款的速度。
(4)政府部门。利用XBRL,企业可以向行业主管部门等政府机关上报各类报表。各行业主管部门可以规定报表的XBRL文件格式,企业通过互联网下载,填报完成后通过网络提交。由于XBRL具有跨平台的优势,报表的传送不受硬件和操作系统等环境的限制。同时,由于这些报表的格式相同,便于政府部门对数据的汇总和分析,实现报表填报、传送和处理的信息化,提高工作效率。例如,企业利用XBRL进行纳税申报,数据直接从会计业务数据库中产生,通过互联网传送到税务部门,不仅保证了数据的真实性,而且也便于税务部门对数据的检查和汇总。
(5)审计机构。随着网络财务信息披露的发展,审计师必将面临对网络财务信息进行审计的需求。XBRL在财务报告中的应用改变了信息的披露方式,提高了审计工作的效率。首先,利用XBRL可以完全突破传统的财务报告按年、季或月发布的模式,做到实时发布,在线披露,便于审计人员实时地了解企业的财务状况,从而做到实时监控;其次,审计人员在阅读财务报告的同时,可以通过超级链接跟踪审计线索,提高了核查的效率;再者,XBRL可以完全突破书面报告格式的限制,财务报告的项目可以分得更加详细,财务报告不仅揭示财务信息,而且可以包含与信息使用者有关的非财务信息。审计工作可以不受时间、地点和空间等因素的限制,使财务信息的获得更加方便,提高审计效率。
(6)投资者。在传统方式下,投资者为了收集数据需要浏览大量财务报告,并将各种数据输入到计算机来分析企业的经营状况,由于数据的来源不同,格式各异,所以分析过程不仅成本高,而且也容易出现输入差错,影响分析结果的准确性。而利用XBRL,投资者能容易地在互联网上进行有目的地定位搜索,并可以进行有机的组合分析,极大地提高了数据分析的效率和准确度。
6.企业会计信息系统导入XBRL的应用方案选择
在已经实现会计信息化的企业,在信息系统中导入XBRL,可以选择以下几种应用方案:
(1)“终端型”应用方案。“终端型”应用方案,即是指企业不需要对原来的信息系统作任何更换或更新,而仅将最后生成的会计报表数据通过人工转换成基于XBRL形式的数据。就目前而言,该方案比较适合我国当前上市公司的实际情况,也是较为可行的方案。首先从成本角度讲,它不需要前期任何投入,也不需要额外增加人力资源成本,而仅在期末略为增加会计人员的工作量即可;其次从技术角度讲,“终端型”应用方案并不需要对当前会计软件做任何改动,而且生成XBRL财务信息所需的软件模板,当前也由深(上)交所设计并提供下载,因此技术障碍也可以忽略不计。这是现阶段我国上市公司信息系统导入XBRL应用较多的方案。但是选择这种方案,并不能充分发挥XBRL的技术优势,而且数据重复录入也容易增加数据的误差,降低数据可靠性,所以“终端型”应用方案只是适合于目前现状的一种权宜方案。
(2)“嵌入型”应用方案。“嵌入型”应用方案,即是指企业要在原来的信息系统基础上,嵌入XBRL格式转换器,由企业信息系统产生各种财务报表,并以电子文档的形式存于EXCEL表格或WORD文档中,当有关机构或部门需要XBRL格式的报表时,由XBRL格式转换器进行转换,转换过程按XBRL分类标准和实例文档要求进行,最后形成XBRL实例文档。这一转换过程是自动完成的,并不会造成数据的丢失和差错,能保证XBRL财务报表与数据源报表的一致性。但这种方案是基于企业原系统生成报表后才能进行转换,因此对产生XBRL格式的报表时间有一定的制约性,另外由于XBRL格式转换器需要购买由软件开发商专门研发的产品,因此选择这种方案在成本上也要高于“终端型”应用方案。尽管如此,由于该方案能有效降低数据转化的失真度,同时还可以节省人工录入数据的时间,所以“嵌入型”应用方案也是当前有条件的企业乐于选择的应用方案。但它仍然没有使XBRL的根本优势得到发挥。
(3)“智能型”应用方案。“智能型”应用方案,即是指将XBRL适配器与企业信息系统有机集成,在信息系统数据处理过程中直接生成符合XBRL规范的会计报表,同时实时产生XBRL实例文档。该应用方案需要企业信息系统的软件供应商研发内嵌XBRL适配器的系统新版本,在业务处理的各个环节将XBRL的“元”数据进行提取和转换,并按照XBRL分类标准,实时生成标准的XBRL实例文档。这是XBRL技术应用的最佳方案,该方案能最大限度地发挥XBRL的技术优势,能够迅速有效地提供实时、便于交流的各类财务信息。“智能型”应用方案要求软件开发商基于XBRL技术对原系统进行功能扩充,内嵌XBRL适配器,而这些功能并不会对原系统的DBMS(数据库管理系统)、系统构架模式和实际应用产生影响,在实际推广中也是一种平滑的过渡。但该应用方案,无论在技术方面还是在资金方面,都将较前两个方案有更高的要求,是一种有未来发展前途的方案。
(三)我国XBRL技术应用的典型案例——深交所“上市公司信息披露电子化规范”实践
为规范我国上市公司信息披露作业流程,解决上市公司信息披露流程中环节、多流转效率低、手工信息处理不准确、不丰富等不足,努力营造“公平、公开、高效”的市场环境,基于XBRL技术,中国证券监督管理委员会牵头组织制定,并于2004年1月经国家金融标准化技术委员会审批通过,并作为行业标准对外发布了《上市公司信息披露电子化规范》(以下简称“规范”)。这一“规范”的颁布,对推动我国上市公司的信息披露规范化和有序发展具有极其深远的意义。深圳证券交易所(以下简称“深交所”)是“规范”制定工作的核心成员,也是在全球率先提出并作为首家尝试将XBRL这一国际化标准应用于上市公司信息披露工作实践的交易所,这在我国乃至世界都具有一定的示范意义。下面,我们就《上市公司信息披露电子化规范》,以及基于这一“规范”深交所实施的网上信息披露实践做简要介绍。
1.《上市公司信息披露电子化规范》简介
《上市公司信息披露电子化规范》严格按照《企业会计》(2003年修订版)和中国证券监督管理委员会关于上市公司信息披露系列准则的相关要求制订,严格依据XBRL 2.1规范和FRTA(Financial Reporting Taxonomies Architecture,即商业报告分类信息框架)的相关规定编写。“规范”涵盖了上市公司定期报告(包括年度、半年度和季度报告)摘要的全部内容。最新版本的分类信息共有模式定义文件(Schema)8个,定义元素(Element)1491个,链接库文件(Linkbase)36个,定义链接关系4593个。
(1)分类信息(Taxonomy)说明
《上市公司信息披露电子化规范》中分类信息(Taxonomy)是一组XML文件,用于定义信息披露中涉及的元素及这些元素间的关系,分类信息(Taxonomy)包括模式定义文件(Schema)和链接库(Linkbase),模式定义文件定义元素名称、ID属性、元素类型等属性,链接库则定义元素间的各类关系。分类信息(Taxonomy)用于规范实例文件的制作及校验。本规范所定义的分类信息遵循XBRL 2.1规范。
分类信息(Taxonomy)具体说明如下:
①公告基本信息分类信息。“公告基本信息分类信息”定义了一系列用于描述公告文件本身信息的元素,通过这些元素,可以详细记录一个公告文件的信息,包括:公告类别、公告标识、公告披露日期、公告披露媒体,以及与该公告文件相关联的商业实体的基本信息,如公司简称、公司代码等。
②上市公司信息披露核心分类信息。“核心分类信息”是各种业务类型的信息披露公告分类信息的扩展基础。
③财务报表分类信息。“财务报表分类信息”提取了上市公司披露信息中涉及财务报表的元素,描述了上市公司定期报告包含的各个财务报表,规范了报表中各会计科目间的勾稽关系和计算关系,确定了上市公司财务数据的命名空间。财务报告分类信息按行业分为工商类财务报表分类信息和金融类财务报表分类信息。
④公告非财务信息分类信息。“公告非财务信息分类信息”定义了上市公司披露信息中除财务报表和相关财务数据以外的信息元素。公告非财务信息包括:公司基本信息;公司股东、股本及权益分派信息;公司筹资、上市及募集资金使用信息;交易和关联交易信息;重大事项信息;公司财务数据信息;其他信息等。
⑤定期报告分类信息。为了满足上市公司定期报告的业务需求而扩展定义的分类信息,它在“核心分类信息”、“财务报表分类信息”、“公告非财务信息分类信息”的基础上进行了适当扩展:界定了定期报告摘要中涉及的披露信息的内容,并重新定义了这些信息(在分类信息中表现为各种元素)的组织方式。定期报告分类信息包括年度报告分类信息、半年度报告分类信息和季度报告分类信息。
(2)分类信息(Taxonomy)结构
分类信息(Taxonomy)命名说明
①分类信息(Taxonomy)中模式定义文件命名约定为:
<分类信息模块标识符>+<版本生效日期>.xsd
其中,<分类信息模块标识符>=‘cn-csrc’+{<行业名称缩写>}+<分类信息模块名称缩写>
——<行业名称缩写>中ci代表工商业,basi代表金融业。在某些模式定义文件中无行业名称属性。
——<分类信息模块名称缩写>中gcd代表公告基本信息,core代表上市公司信息披露核心信息,pfs代表财务报表,nf代表非财务信息,ar代表年度报告,sar代表半年度报告,qr代表季度报告。
——<版本生效日期>中本次的版本生效日期为2004-12-31。
例如,工商类上市公司年度报告摘要的模式定义文件名为:cn-csrc-ci-ar-2004-12-31.xsd。
②链接库的命名约定为:
<分类信息模块标识符>+<版本生效日期>+<链接库类型>.xml
其中,<分类信息模块标识符>的定义和取值范围与模式定义文件中<分类信息模块标识符>一致,<版本生效日期>的定义和取值范围也与模式定义文件中<版本生效日期>一致。<链接库类型>分为五类,具体如下:
——Label:代表标签链接库,为模式定义文件中包含的元素定义个性化的标签,以便展现时使用。
——Presentation:代表展示链接库,描述模式定义文件中包含的元素的展现顺序。
——Calculation:代表计算链接库,描述模式定义文件中包含的元素之间的计算关系。
——Definition:代表定义链接库,描述模式定义文件中包含的元素之间的层次结构关系。
——Reference:代表参考链接库,为模式定义文件中包含的元素提供参考信息,如:元素来源依据。
例如,工商类年度报告的展示链接库文件为:cn-csrc-ci-ar-2004-12-31-presentation.xml。
一个模式定义文件通常和一个或多个链接库文件相关联。
(3)实例文件说明
实例文件是XBRL应用示范项目的数据源,在本项目中特指由本项目提供的符合XBRL2.1规范的,包含上市公司定期报告摘要数据的XML文件。实例文件(Instance)记录了上市公司披露定期报告摘要的具体信息内容,实例文件的元素严格符合分类信息(Taxonomy)模式定义文件(Schema)中关于该元素的相关定义(包括元素名称、数据类型、元素类型等),同时实例文件的元素间关系也严格符合分类信息(Taxonomy)链接库(Linkbase)中关于元素间的关系定义(主要是计算链接库中定义的会计科目间的勾稽关系)。实例文件除包含分类信息(Taxonomy)中规定的元素外,还包括关于单位定义和上下文定义的元素。单位定义元素主要定义数据元素的单位(如元、千元、股等),上下文元素定义数据元素的上下文(如报表年度、报表类型等)。 实例文件的命名的规则为:
CN_SZ_<公司代码>_<公告分类编码>_<公告编号>_<提交日期>
比如,实例文件样例:CN_SZ_000002_GB0110_2004001_20041024.xml。
2.深交所基于《上市公司信息披露电子化规范》实施网上信息披露的实践
基于《上市公司信息披露电子化规范》,深交所于2004年6月开始了上市公司网上信息披露的实践,其具体分为以下三个步骤进行:
(1)上市公司XBRL财务报告文件的生成
为了推动上市公司使用XBRL技术制作信息披露文件,深交所深入研究了上市公司信息披露全程电子化业务模式,于2005年1月正式推出改版后的基于XBRL的“上市公司定期报告制作系统”。目前深交所的全部上市公司将利用该系统制作年度报告。上市公司通过该系统提供的模板和有关工具填写信息披露的有关数据,经过勾稽关系、完整性等校验后,同时生成信息披露文件(即公告文件和PDP文件)及符合XBRL标准的实例文件,提高了上市公司信息披露文件的编制的规范性、准确性。
(2)上市公司XBRL数据流转、交换与共享
由于XBRL规范的开放性,基于XBRL规范的实例文件还可以广泛用于数据交换,而且可以实现不同硬件平台、不同操作系统和不同数据库之间的数据交换。在XBRL规范下,数据交换方在获取实例文件后,只需依据“规范”制订的分类信息(Taxonomy)即可进行实例文件的校验和解析,从中获取部分或全部信息。数据交换方也可以依据“规范”制订的分类信息(Taxonomy)从自己的数据库(或其他信息存储方式)中抽取数据、校验并生成实例文件,并提供给第三方进行数据交换。
(3)上市公司XBRL数据的展示
深圳证券交易所在自己的网站上开通了一个“XBRL应用示范”页面,为投资者提供了基于XBRL实例文件的Web分析工具,通过图形化的界面直观地展示深交所成分股指数样本公司的数据对比分析结果,同时完成了最近5年的历史数据转换工作,并提供了直接生成实例文件的辅助制作工具,使需要使用披露信息者可以从上市公司获得实例文件并直接使用Web分析工具进行数据展示和分析。
“XBRL应用示范”的推出,为普通中小投资者提供了实用高效的分析工具,使他们能够以更低的成本、更高的效率实现信息的生成、提取、分析、交换和共享。过去上市公司信息网站只发布PDF格式的文件,专业的分析工具只有付费后才能获得,往往只有专业机构才有能力购买这些分析工具,使普通中小投资者在获取更多上市公司信息方面处于弱势地位。“XBRL应用示范”的具体功能主要有:
①提供丰富的公司财务数据和指标。不仅提供资产负债表、利润及利润分配表、现金流量表和股本结构表等的原始数据,而且还提供11个比率类指标,包括4个偿债能力指标、2个盈利能力指标、3个经营能力指标及2个资本构成指标。
②展示深成指样本公司(金融类公司除外)近5年年报历史数据,数据跟随最新年报披露情况持续更新,所有展示数据XBRL 实例文件可直接下载。同时也可提供深市所有上市公司的近5年历史实例文件下载的功能。如图2-9所示。
③单个公司多年度各项指标的纵向比较,操作简便,只需三步,立即可以图形化方式直观揭示公司财务状况走势,并有鼠标悬停提示,在观察走势的同时可精确掌握具体数值。如图2-10所示。
④同时提供多公司、多年度、多指标的立体分析结果,公司对比情况一目了然,并有鼠标悬停提示,在观察走势的同时可精确掌握具体数值。
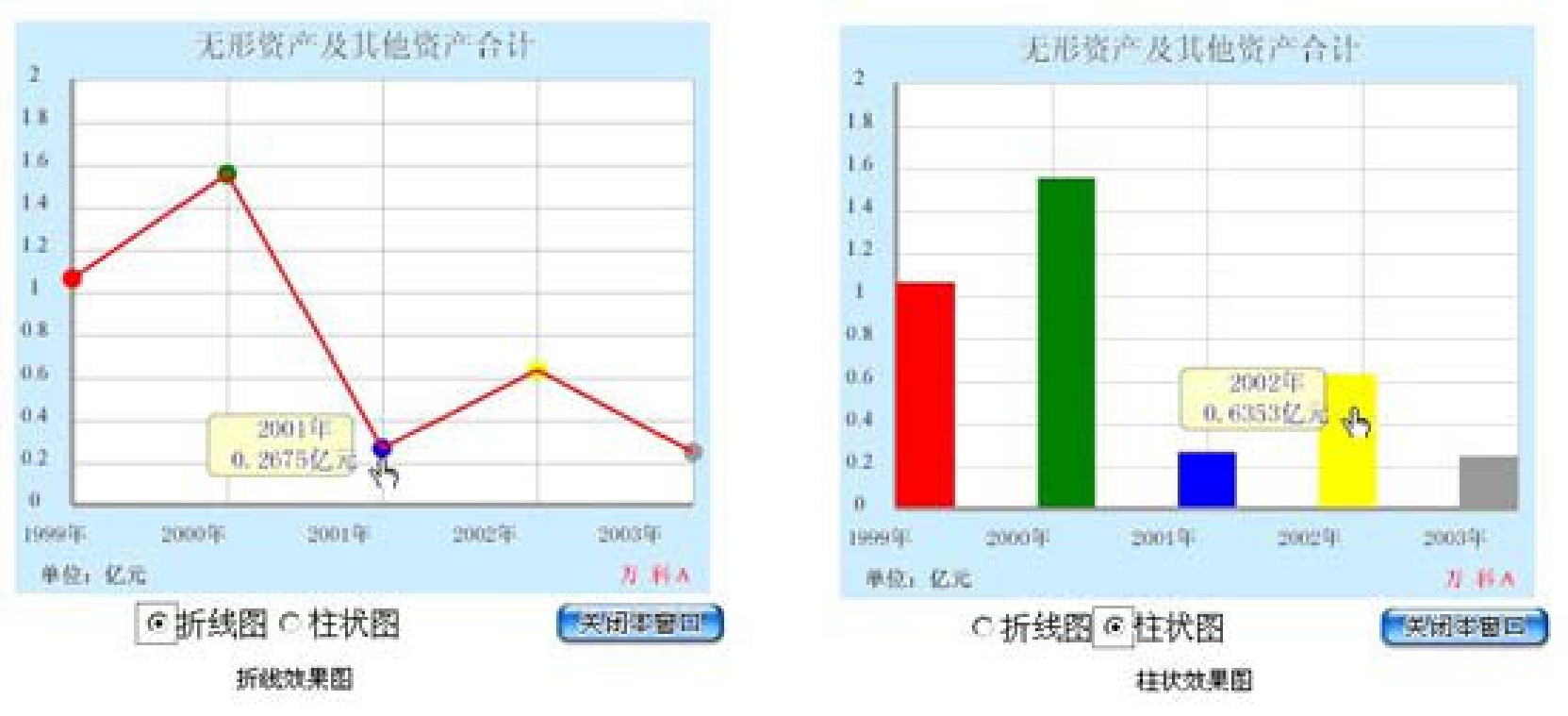
图2-9 上市公司财务指标综合比较
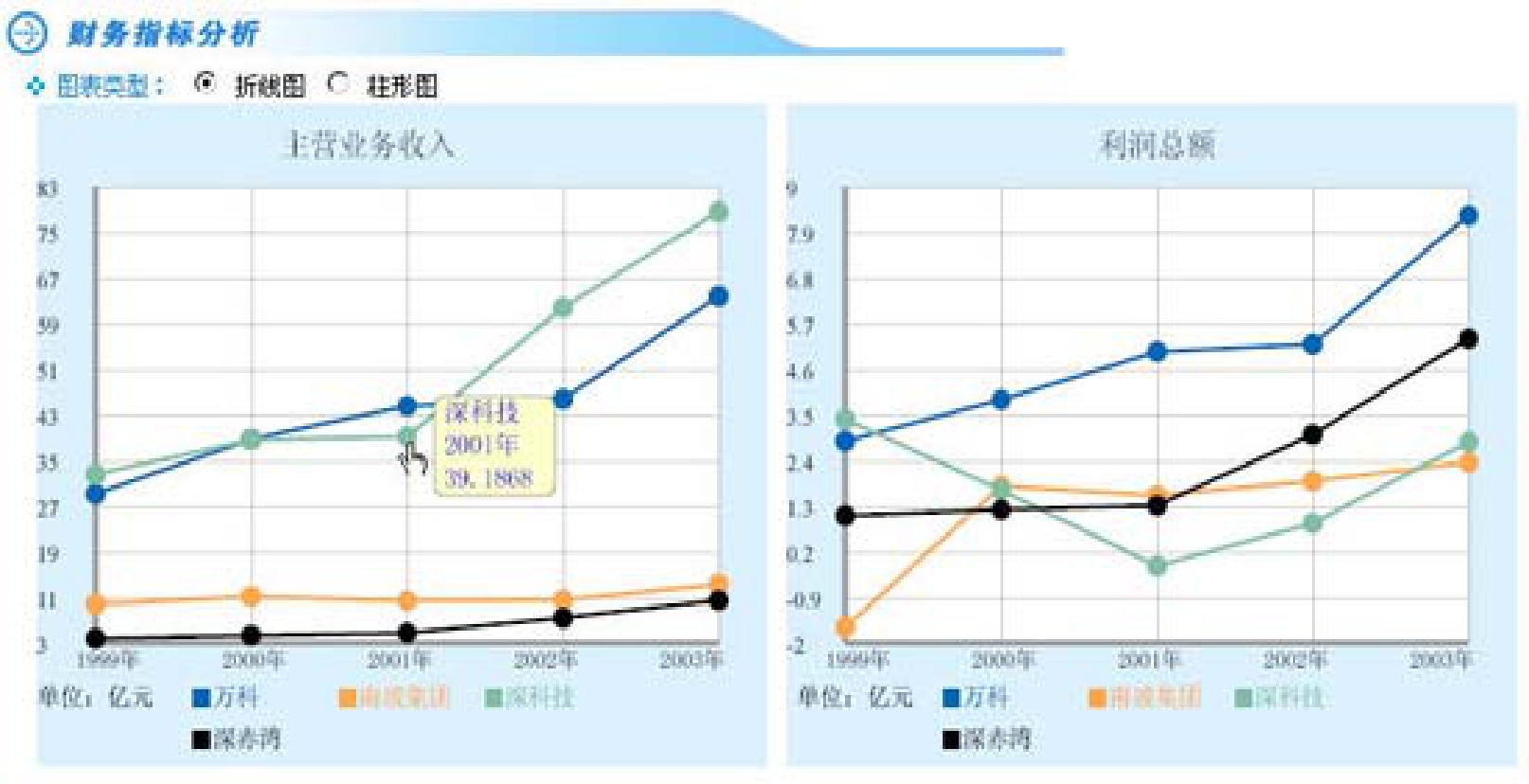
图2-10 上市公司财务指标纵向比较
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。











