



6.4.6 PLSR的MATLAB实施与应用
MATLAB中自带函数plsr采用NIPALS算法进行偏最小二乘回归,该函数调用命令如下
>>[theta,w,cw,ssqdif,yres]=plsr(xreg,yreg,nu,lv,plotopt)
%plsr函数输入变量的含义:
%xreg与yreg分别为建模集中自变量和因变量矩阵;
%nu:自变量个数(即矩阵xreg的列数);lv为使xreg与yreg协方差最大的PLS向量个数(即潜变量-PLS成分个数);
%plotopt默认值=0,此时无图形输出,
%plotopt=1,画出各样本的实际因变量(yreg)与plsr模型给出的因变量(yfit);
%plotopt=2,画出yreg、yfit及因变量残差(yres).
%plsr函数输出变量的含义:
%theta:n×nu维响应系数矩阵,第i列对应自变量i的响应系数。plsr模型给出的因变量yfit=xreg*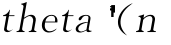 为因变量个数,plsr函数默认n=1,n大于1时该函数不能正常调用,故theta实际是一元素个数=自变量个数的行向量。
为因变量个数,plsr函数默认n=1,n大于1时该函数不能正常调用,故theta实际是一元素个数=自变量个数的行向量。
%w及cw为确定theta的中间矩阵和向量。
%ssqdif:PLSR解释的自变量和因变量方差百分率;
%yres:因变量残差
plsr.m文件可以在MATLAB
function[theta,ssqdif,yres,t,Tcrit,R,F,Fcrit,yu]=pls_test(xreg,yreg,LV,xpre,alpha)
%偏小二乘回归建模、预测并对回归模型和回归系数进行检验的程序
%xreg为建模集自变量;yreg为建模集因变量;alpha为置信水平,取0.05或0.01
%LV为潜变量个数(LV≤自变量个数)
%xpre为预测集的自量矩阵(如果不做预测,xpre输xreg即可)
%输出变量:theta为plsr回归系数组成的行向量,其个数=自变量个数+1
%ssqdif:PLSR解释的自变量和因变量方差百分率;yres:因变量残差.
%t为按照4-19计算的LV个潜变量的回归系数统计检验量,Tcrit为t分布的临界值
%R为plsr回归模型的复相关系数;
%F为plsr回归所得回归模型的方差比值统计量,Fcrit为F分布的临界值
%yu为plsr回归模型给出的未知样本的因变量值

%对建模集自变量矩阵(每一列为一个自变量)进行自标度化处理并将结果赋给矩阵ax,返回参数mx与s分别为各变量的均值与标准方差
%自编函数autoscaling见6.1.3的m文件autoscaling.m
[theta,w,cw,ssqdif,yres]=plsr([ones(nx,1)ax],yreg,px+1,LV);
%以含常数列的ax为自变量,yreg为因变量进行偏小二乘回归
Yc=[ones(nx,1)ax]*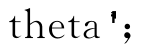 %求建模集因变量并赋给Yc
%求建模集因变量并赋给Yc
ym=mean(yreg);%求因变量的均值
Sc=sum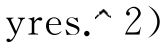 ;%求建模集残差平方和
;%求建模集残差平方和
Sh=sum((Yc-repmat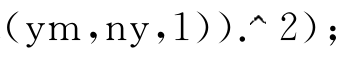 ;%求回归平方和
;%求回归平方和
R=sqrt(Sh/sum((yreg-repmat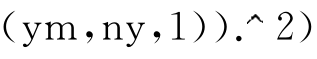 ));
));
%求plsr回归模型的复相关系数R
F=(nx-LV-1)*Sh/(LV*Sc);%求plsr回归模型的统计检验量F比值
Fcrit=finv(1-alpha,LV,nx-LV-1);%求F分布的临界值
R,F,Fcrit %屏幕显示R,F,Fcrit的值
%以下计算plsr回归系数(不含常数项)显著性检验的统计参数t值
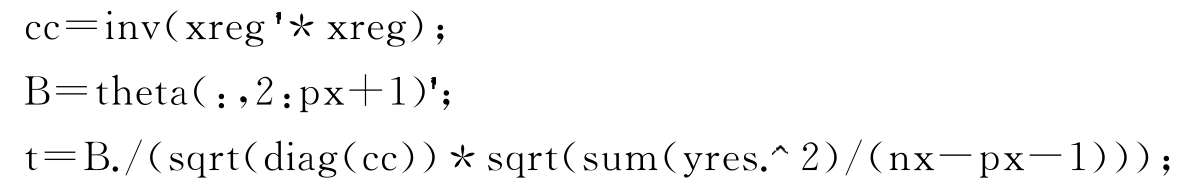
%根据式(4-19)计算实际统计量t所组成的列向量(不含常数项)
Tcrit=tinv((1-alpha/2),nx-px-1);%求t的临界值
t,Tcrit%屏幕显示t,Tcrit的值
%下面根据建立的plsr回归模型预测未知样本的y值
[np,pr]=size(xpre);
%将矩阵xpre的行数和列数分别赋给变量np,pr
axp=(xpre-repmat(mx,np,1))./repmat(s,np,1);
%将预测集样的自变量减建模集对应变量的均值并除以该变量的方差(对预测样本进行自标度化预处理)

plsr.m函数中没有优化潜变量LV的功能,需要每次调用时人为输入LV个数,当自变量个数nu较大时,依次选取LV=1~nu调用plsr并比较不同LV下的结果以选取合适的LV建模很麻烦。利用留一交叉验证原理,我们自编了优化LV的MATLAB函数如下
function[lv,theta,ycal,t,Tcrit,STATUS,ypre]=pressf(X,Y,xpre,alpha)
% pressf(留一法确定潜变量个数)
% 输入变量:
% X,Y:自变量与因变量矩阵;xpre为预测集自变量矩阵
% 输出变量:
% lv:最佳PLS潜变量个数,theta:PLSR回归系数向量,含义同plsr.m% ycal-根据优化的lv所确定的plsr模型给出的因变量值;% t为对theta给出的各plsr回归系数进行显著性检验的统计量t(不含常数项),其大小=nox(X的列数);
% Tcrit为t双边分布函数在nox-lv-1自由度下的临界值(置信水平=alpha)
% STATUS存储最佳lv值下所得plsr模型的评价指标:其第1个元素r为建模样本的模型值与实测值之间的相关系数;
% 第2个元素为RMSEC(建模样本的均方根误差);第3个元素e为模型给出的因变量值与实际值的绝对平均残差;
% 第4个元素R为plsr回归模型的复相关系数;
% 第5个元素F为plsr回归模型检验的统计量F比,F大于第6个元素Fcrit(F的理论临界值)时模型可以通过显著性检验。

%计算每个LV下留一检验样本的y值
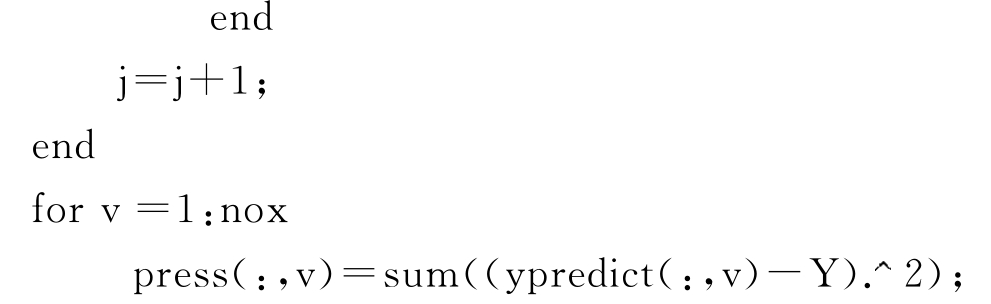
%计算对应的潜变量下的留一检验样本的因变量残差平方和press
end
plot(1:nox,press )%画出press随pls潜变量个数的变化图
)%画出press随pls潜变量个数的变化图
[pressvalue,a]=min(press);%a=press最小时的潜变量个数
lv=a;
[theta,ssqdif,yres,t,Tcrit,R,F,Fcrit,ypre]=pls_test(X,Y,lv,xpre,alpha);
%调用pls_test自编函数计算最佳潜变量下的plsr回归系数并对回归模型和回归系数进行统计检验
ycal=[ones(nrx,1)ax]*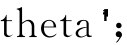 ;
;
RY=corrcoef(Y,ycal);
r=RY(1,2);%计算最佳LV下建模集模型值与实际值之的相关系数
RMSEC=sqrt(sum((Y-ycal).2)/nry);%计算建模集均方残差
e=abs(yres);%计算建模集因变量的残差绝对值
rmse=mean(e);%计算建模集因变量的平均绝对残差
STATUS=[r RMSEC rmse R F Fcrit];
%将最佳plsr回归模型的评价指标赋给STAUS数组
%end of pressf
例6-6 用PLSR求例4-3中的4个自变量与因变量间的回归关系并确定最佳潜变量LV值,对最佳LV对应的PLSR回归模型及模型参数进行统计检验。在输入自变量数据矩阵X与因变量矩阵y后,在MATLAB下输入如下命令
>>[lv,theta,ycal,t,Tcrit,STATUS,ypre]=pressf(x,y,x,0.05)
可得如下结果

这表明,最终pressf函数根据留一交叉验证选取了3个pls潜变量,这3个pls成分体现了69.2%的自变量信息、99.95%的因变量信息。图6-18为PRESS随潜变量个数a变化的趋势,根据该图,在a=3时,PRESS达到最低点,随后当a=4时上升。故最佳潜变量个数LV=3。
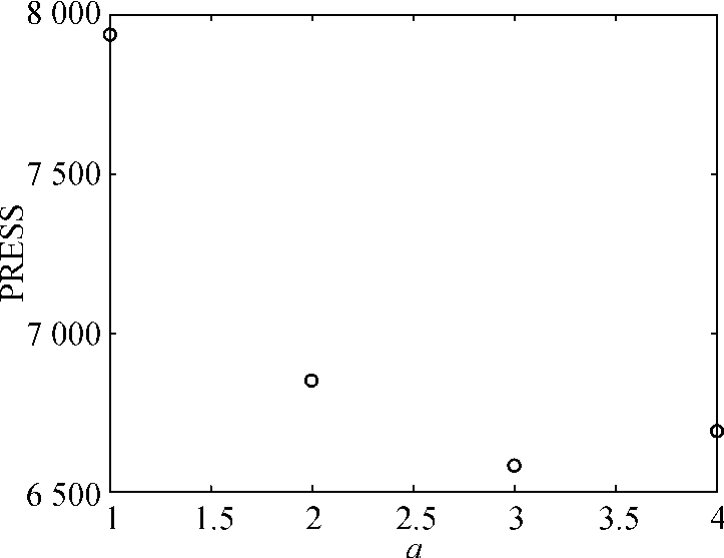
图6-18 交叉验证预测残差平方和PRESS随潜变量个数a的变化
![]()
(3个潜变量下获得的plsr回归模型的复相关系数为0.9881)

4个自变量前的plsr回归系数的统计量t的绝对值均大于t的临界值(2.306),故该回归方程的回归系数均可通过显著性检验。
![]()
根据theta向量可知LV=3时的plsr回归方程为
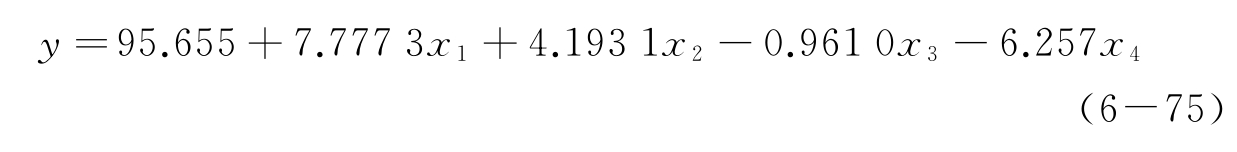
打开STAUS得
![]()
根据其第一个数值可知,回归模型(6-75)给出的因变量y值与y的实际值之间的相关系数r=0.988 8;由STATUS的第二个数值可知回归模型(6-75)的均方根残差RMSEC=2.16;由STATUS的第三个数值可知模型(6-75)的因变量平均绝对残差=1.826 2。
显然,LV=3时PLSR回归模型(6-75)的误差比表4-6中方程(4-18)的误差略高,但比表4-6中只取x1、x2回归所得方程(4-21)的误差小,并且方程(6-75)所反映的自变量与因变量之间的关系与表4-5所体现出的y随x1、x2的增长而增大、随x3和x4的增大而减小的基本规律相符。表明偏最小二乘回归避免了例4-3中采用多元线性回归得到的回归方程(4-18)中y与x3成正相关关系的谬误,并且取得了良好的回归精度。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。











