



如何整理学术文献?

□nerfing
我认为整理文献的主要目的是:能够在任何条件下,快速找到所需信息。任何详尽的分类,都不如好用的搜索工具。
我的思路是:重搜索,轻整理。重搜索,是指利用不同的搜索工具,快速定位到所需文献。轻整理,是指不对文献分类,或者只是对文献简单分类。我认为在现在搜索技术已经很强大的情况下,如果利用笔记等手段整理,反而容易造成条条框框,对于一篇文献关注太长的时间,不利于提高效率。除了在文献 PDF 上直接标注,我很少用其他的软件去记录看过的文献。因为除了文献本身,没有其他载体能够详尽提供所需信息。所以整理文献问题就成了:如何快速找出那篇有笔记的 PDF 文献。以此为目的,我建立了一套以文献 PDF 云同步为基础,辅以大量搜索工具的文献整理方案。
其实做过科研工作的人都会发现,真正需要把一篇文献从头到尾读完的情况是很少的。在大多数情况下,需要的其实是大批量多轮次地阅读文献,因为在一个项目的不同阶段,哪怕是同一篇文献,所关注的信息点也是不一样的。如果在项目初期,就对所有的文献,都投入同样的时间,阅读同样的深度,势必会浪费大量时间和无用功。我曾经也走过文献整理的弯路,每阅读一篇文献,都会在 Onenote 上建立一个条目,按照文献题目、创新点、实验过程、个人感想等分别填空。但是文献读得多了之后,我觉得这个方法效率不高,用的频率也越来越少了。
我现在的主要方法是:以 Mendeley 建立电子文献索引为主,并以云端同步 PDF 文献为主要储存手段,通过 Everything、Google Scholar、桌面搜索软件、Onenote 笔记等多种搜索手段,快速找到自己所要的信息。
1. 构建文献库
在新项目(写一篇综述,开始一个新课题或者完成一份大作业)开始之前,我会在 Mendeley 中根据不同项目,建立一个新文献库。

比如现在需要关注一下微流控单细胞测序的最新进展,在 Web of Science 搜索 microfluidic single cell sequencing。
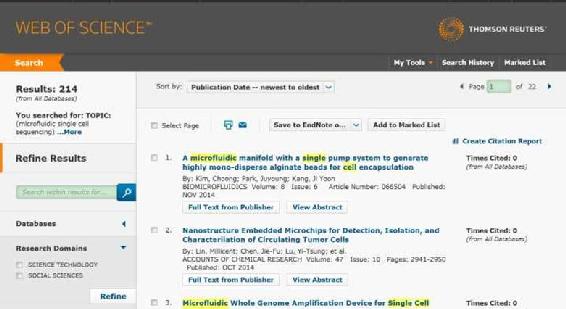
总共有 214 篇文献。我会把 214 篇文献的题目先全部浏览一遍,下载其中大约 100 篇并浏览后,最后会剩下大约 50 篇文献。
把下载的文献拖进 Mendeley,建立原始的文献积累。Mendeley 会自动提取文献信息。设置 Mendeley,使其按照文献的发表年份、期刊和文章题目将文献 PDF 文件重命名,并将该 PDF 文件自动整理到同一个文件夹中。
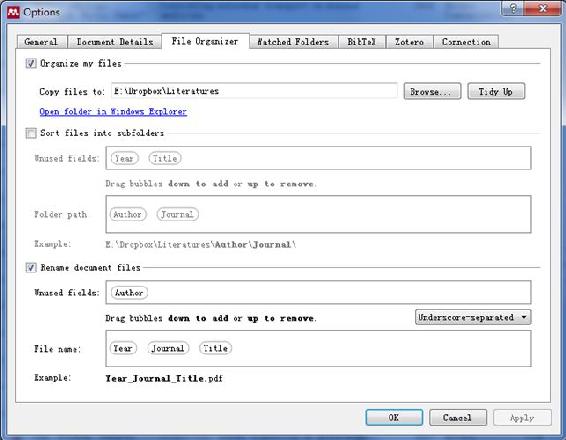
我的 Mendeley 设置
之后将这些下载的文献通读一遍。一边阅读,一边在文献 PDF 上做笔记,这样就不用另外开一个软件写笔记,并可以对自己感兴趣的信息直接标注。哪怕打印了纸版的文献,也可以在看完后按照纸版笔记在 PDF 上标注,最大可能避免信息碎片化。将这个文献文件夹用 Dropbox 云同步,这样在不同的电脑上,也可以阅读同一个文献 PDF。

标注的文献 PDF
2. 搜索文献
第一重搜索,利用 Everything 的强信息搜索。
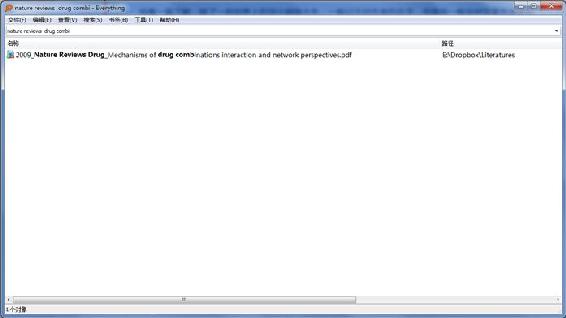
我习惯把一篇文献的发表年份、期刊和文章题目认为是一篇文献的强信息,我一般会对文章发表年份和所在期刊有很深的印象,而文章题目又提供了文章中最主要的信息。在构建文献库的时候,Mendeley 已经根据文献发表年、发表期刊和文章题目对文献 PDF 自动重命名,利用 Everything,就可以在本地实现文献的第一重搜索。
如果搜索目标很明确,比如我现在想找一篇之前在 Nature Drug Review 上看过的关于 drug combination 的文章,由于关键词很明确,用 Everything 直接就从本地找到了,耗时不超过 3 秒。
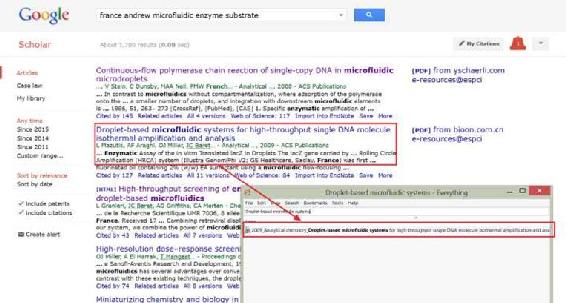
第二重搜索,利用 Google Scholar 的模糊搜索。
如果搜索目标不那么明确,「总感觉有些文献读过就忘记了,想用的时候想不起来」;或者想找一些特定的问题,不确定本地文献有没有。这个时候我一般会输入所有能想到的关键词,上 Google Scholar 搜索。比如有的时候,我需要某一种酶底物的合成路线,我只是依稀记得法国 Andrew Griffiths 课题组似乎有做过类似的研究,于是我就把关键词「France Andrew microfluidic enzyme substrate」全部输入到 Google Scholar 中搜索。如下图中,可能会找到一些文献在本地是有的,那就可以根据文献名,用 Everything 快速在本地找到对应的文献。
如果一些文献本地没有,那就直接下载 PDF,阅读后在 Mendeley 建立本地索引。
如果想要搜索特定一句话,或者在写文章的时候想对一些说法进行佐证,就可以用 Mendeley 的搜索工具。
或者还是上 Google Scholar。

3. 轻整理部分
之后随着时间的流逝,一个文献库下的文献慢慢变多,这个时候就需要在 Mendeley 中建立子文件夹了(对于我来说,每个项目中前前后后需要阅读的文献大概 300 篇),也就是传统意义上的整理。但是我不赞成把文献归类做得过细。在一个项目下简单分类,使每个子文件夹中的文献大概不超过 50 篇,再通过发表年份、期刊名、作者名等信息,也可以很容易找到所需的文章了。
但是我不会等文献很多了之后再去建立子文件夹,而是会在平时读文献的时候,根据一个项目下的不同问题,建立一些小的分类。在 Mendeley 中,同一篇文献是可以归属不同的文件夹的,所以在归文件夹的时候也不用那么纠结。

Q&A
1. 为什么用 Mendeley 构建文献库?
我用 Mendeley 而不是 Endnote 构建文献库,主要是因为 Mendeley 是我用过所有的文献整理软件中,提取文章题目、发表年份和期刊等信息最准确和方便的软件。看到一篇有意思的文章,只需要导入 Mendeley,它就会自动提取文献信息建立条目,并将文件拷贝到指定文件夹中。其他的软件,要么是提取文献条目的准确度不高,要么就是建立文献条目非常麻烦,需要花大量的时间去建立条目,大大降低文献阅读效率。
2. 为什么用发表年份、期刊和文章题目将文献重命名?
我认为这三者是一篇文献里最直观的信息,这三个信息在之后的搜索中会经常用到。
3. 为什么要将所有的 PDF 文献放到同一个文件夹下?
把所有的文献全部放到同一个文件夹下,这样之后在其他项目中如果用到同样文献,就可以打开同一篇 PDF 文件。之后要阅读文献时,只从这个文件夹中打开文献。这样做的好处就是,把所有的文献和笔记信息全部集中化了,不会造成信息碎片。
最后,我想说的是,任何文献整理软件都不能代替人对文献的阅读,任何时候,读懂文献中的信息永远是第一位的。整理软件只能够帮助你更加快速地找到所需的信息而已。
2015-04-12
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。









