



7.5 中文分词系统介绍
7.5.1 分词系统的评价标准
分词系统的最主要的工作是进行分词。对于分词而言,不仅要求所研制的软件在分词的正确率和速度方面满足一定的要求,而且要像开发大型传统软件那样,在各个阶段不断地进行评价,其目的主要是检查它的准确性和实用性,分词系统的评价主要有以下几个方面:
(1)分词正确率
书面汉语的文本可以看成是字符序列,分词的正确率直接影响更高一级的处理。现有的分词系统切分错误主要集中在歧义字段和专有名词(如人名、地名、机构名和未登录词等)。为了获得更高的切分正确率,应该进行整体测试、歧义测试和专业词测试,最终结果应为三种测试的加权值。
(2)切分速度
切分速度是指单位时间内所处理的汉字个数。在分词正确率基本满足要求的情况下,切分速度是另一个很重要的指标,特别对于算法不单一、使用辅助手段,诸如联想,基于规则,神经网络,专家系统等方法更应注意这一点。通常中文信息处理的文本数量是相当大的,因此必须考虑方法是否能使系统总开销合理。在人机交互方式下处理歧义问题的策略和人机接口的设计,有时会严重地影响切分速度,这也是应该考虑的因素。
(3)功能完备性
自动分词方法除了完成分词功能外,还应具备词库增删、修改、查询和批处理等功能。
(4)易扩充和可维护性
这是提供数据存储和计算功能扩充要求的软件属性,包括词库的存储结构,输入/输出形式的变化等方面的扩展和完善。这项指标与系统清晰性、模块性、简单性、结构性、完备性以及自描述性等软件质量准则有直接的联系,对于研究实验性质的软件是非常重要的,因为这类软件需要不断提高与改进,使之适应中文信息处理的各种应用。
(5)可移植性
可移植性是指方法能从一个计算机系统或环境转移到另一个计算机系统或环境的容易程度。一个好的分词方法不应该只能在一个环境下运行,而应该稍作修改便可在另一种环境下运行,使它更便于推广。
另外,对于中文分词系统而言,由于汉语的复杂性和特殊性,中文分词系统还存在两个指标性的能力评价标准:歧义切分能力和未登录词的识别能力。
由于可能存在歧义,分词并不是一个简单地从输入串中发现合法词的过程。一个句子经常对应几个合法词序列,因此,汉语分词中的一个重要问题就是在所有这些可能的序列中选出一个正确的结果。歧义切分是自动分词中不可避免的现象,是自动分词中一个比较棘手的问题。对歧义切分字段的处理能力,严重影响到汉语自动分词系统的精度。实践表明,只用机械匹配进行分词,其精度不可能高,虽然有时也能满足一些标准不高的需要,但不能满足中文信息处理高标准的要求。
未登录词辨别,未登录词包括中外人名、中国地名、机构组织名、事件名、货币名、缩略语、派生词、各种专业术语以及不断发展和约定俗成的一些新词语。它是种类繁多,形态组合各异,规模宏大的一个领域。对这些词语的自动辨识,是一件非常困难的事。
7.5.2 各中文分词系统概述
目前使用较广泛的中文分词系统有中国科学院开发的ICTCLAS,哈尔滨工业大学开发的哈工大分词系统,北京航空航天大学开发的汉语自动分词使用系统CASS(Chinese Automatic Segmenting System),清华大学开发的SEG-SEGTAG,复旦大学开发的复旦分词系统,杭州大学改进MM算法开发的MM系统,北京大学计算语言研究所开发的北大分词系统,以及Microsoft Research汉语句法分析器中的自动分词系统。
中科院ICTCLAS(Institute of Computing Technology,Chinese Lexical Analysis System)是一个基于多层隐马尔可夫模型的汉语词法分析系统。该系统的功能有:中文分词;词性标注;命名实体识别;新词识别;同时支持用户词典。分词正确率高达97.58%(最近的973专家组评测结果),基于角色标注的未登录词识别能取得高于90%召回率,其中中国人名的识别召回率接近98%,分词和词性标注处理速度为31.5KB/s。
哈工大统计分词系统能够利用上下文识别大部分生词,解决一部分切分歧义。经测试,此系统的分词错误率为1.5%,速度为236字/秒。
CASS系统由总控程序、自动分词程序、设施管理程序、分词词典和知识库等五大部分组成。自动分词算法程序选用正向增字最大匹配法ASM(+1,+ 1,+1)实现,该算法的嵌套调用,可以识别出各种多义切分字段,包括任意多重的交集型多义字段。这个算法经过相应的运行控制,可以实现其他各种分词算法。其机械分词速度为200字/秒以上,知识库分词速度150字/秒(没有完全实现)。
清华大学SEG分词系统提供了带回溯的正向、反向、双向最大匹配法和全切分-评价切分算法,由用户来选择合适的切分算法。其特点则是带修剪的全切分-评价算法。经过封闭试验,在多遍切分之后,全切分-评价算法的精度可以达到99%左右。清华大学SEGTAG系统着眼于将各种各类的信息进行综合,以便最大限度地利用这些信息提高切分精度。系统使用有向图来集成各种各样的信息。通过实验,该系统的切分精度也可达到99%左右,能够处理未登录词比较密集的文本,切分速度约为30字/秒。
复旦分词系统FDASCT由四个模块构成。预处理模块,利用特殊的标记将输入的文本分割成较短的汉字串,这些标记包括标点符号、数字、字母等非汉字符,还包括文本中常见的一些字体、字号等排版信息。歧义识别模块,使用正向最小匹配和逆向最大匹配对文本进行双向扫描,如果两种扫描结果相同,则认为切分正确,否则就判别其为歧义字段,需要进行歧义处理;歧义字段处理模块,此模块使用构词规则和词频统计信息来进行排歧。最后,此系统还包括一个未登录词识别模块,实验过程中,对中文姓氏的自动辨别达到了70%的准确率。系统对文本中的地名和领域专有词汇也进行了一定的识别。
杭州大学改进的MM分词系统的词典采用一级首字索引结构,词条中包括了“非连续词”(形如C1□* Cn)。系统精度的实验结果为95%,低于理论值99.73%,但高于通常的MM,RMM,DMM方法。
北京大学研究所分词系统由北京大学计算语言学研究所研制开发,术语分词和词类标注相结合的分词系统。系统的分词连同标注的速度在Pentium 133Hz/16MB内存机器上的达到了每秒3千词以上,而在Pentium II/64MB内存机器上速度高达每秒5千词。
微软研究院的自然语言研究所从20世纪90年代开始开发了一个通用型的多国语言处理平台NLPWin,据报道,NLPWin的语法分析部分使用的是一种双向的Chart Parsing,使用了语法规则并以概率模型做导向,并且将语法和分析器独立开。实验结果表明,系统可以正确处理85%的歧义切分字段,在Pentium 400PC上的速度为900~1200字/秒。
7.5.3 中科院分词系统I CTCLAS
7.5.3.1 系统介绍
中文分词系统ICTCLAS(Institute of Computing Technology,Chinese Lexical Analysis System)是中科院计算所的张华平、刘群开发的,系统采用C++语言开发。它是一套获得广泛好评的分词系统,其主要功能包括中文分词、词性标注、命名实体识别、新词识别等,同时支持用户词典,也就是说用户可以通过自定义一个词表来扩充ICTCLAS的原有词库。该组件先后经过五年的精心打造,内核升级6次,目前已经升级到了ICTCLAS3.0。ICTCLAS3.0分词速度单机996KB/s,分词精度98.45%,API不超过200KB,各种词典数据压缩后不到3M,是当前世界上最好的汉语词法分析器。
该分词系统的主要思想是先通过层叠形马尔可夫模型CHMM(Cascaded Hidden Markov Model)进行分词,通过分层,既增加了分词的准确性,又保证了分词的效率,共分五层,如图7-2所示。
分词的流程大概是:先进行原子切分,然后在此基础上进行N最短路径粗切分,找出前N个最符合的切分结果,生成二元分词表,然后生成分词结果,接着进行词性标注并完成主要分词步骤。各部分说明如下:
——原始字符串:分词的基本单元,常常是指一个句子。它在文章中由各种标点符号拆分,得到基本分词单元;
——原子切分:将原始字符串打散为单个汉字等不可再拆分的单元;按照上面所提到的汉字为单个的字,数值为连续的数字,英文为连续的英文字符,其他的标点符号为单独的一个字符的思路来实现的。
——N最短路径粗切分:是最短路径和最大路径的折中,保留前N个最优路径,获得最优的前N个切分结果,既能达到一个比较理想的分词效果,又能保证分词的速度。
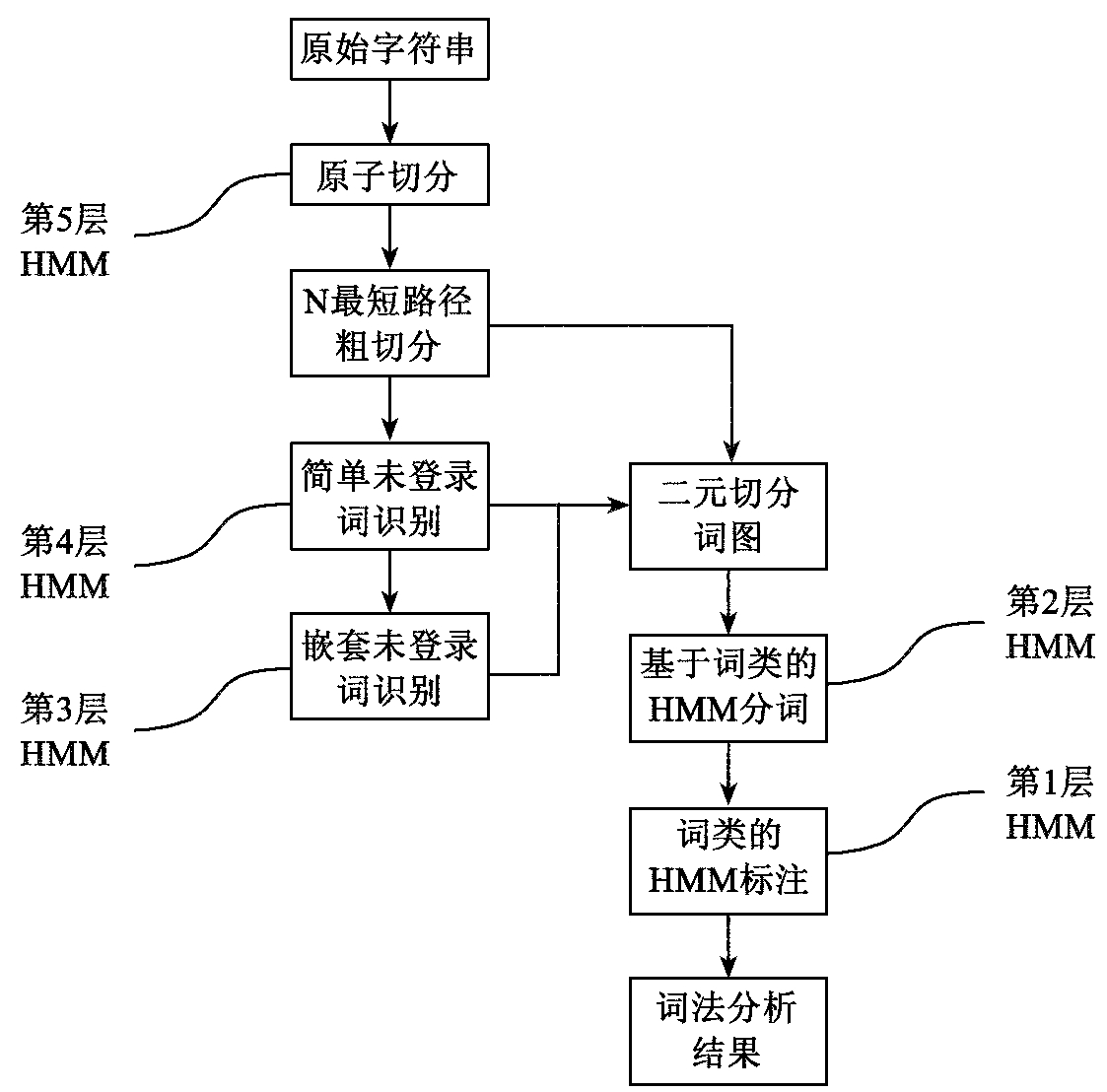
图7-2 基于CHMM的汉语词法分析框架
——简单未登录词识别:通过简单的人名、地名等未登录词的识别,优化粗分结果,得到修正的前N个最优切分结果;
——嵌套未登录词识别:通过复杂的地名、机构名识别,再次优化N个粗分的结果;
——基于词类的HMM分词:基于HMM模型,通过词类信息,优化粗分结果;
——词类的HMM标注:基于HMM模型,标注词性,得到最终的词法分析结果。
7.5.3.2 ICTCLAS分词实验
下面我们使用ICTCLAS系统进行一个简单的分词实验,并对结果进行分析。
(1)安装相应软件,配置好环境变量,在网站上获取ICTCLAS3.0。
在http://www. i3s.ac. cn下载ICTCLAS3.0分词组件,其中ICTCLAS30.dll就是所需要的动态链接库文件,将它复制到新建的eclipse工程项目的根目录下。将data文件夹也一并复制到项目根目录,data文件夹是ICTCLAS的概率数据文件,程序将利用它来进行辅助分词。在下载的组件中有一个Licenses文件夹,运行里面的exe程序注册,获得注册码,然后将Licenses文件夹中的user. lic文件、组件文件夹中的Configure.xml文件一并复制到工程的根目录下,同时将组件包中的/api/JNI下的文件也复制到工程中。配置好的Eclipse工程的目录结构如图7-3所示。
图7-3 ICTCLAS3的工程目录
Userdict. txt是用户的自定义词典文件,用户可以在该文件中加入ICTCLAS词典中没有的新词来满足具体的需求。
ICTCLAS是用C/C++编写的,因而其编译后是动态链接库文件,在Java中调用时要在静态初始化阶段加载它。在ICTCLAS的最新3.0版中,提供了JNI调用的API,但是要注册申请后只能试用一个月,之后如果再需要使用就要购买。因此使用ICTCLAS有一定的限制,在分词实验方面还可以使用一些其他的分词组件,如JE分词组件,IKAnalyzer等组件。
(2)编写程序利用JNI调用ICTCLAS对一段中文文字进行切分
ICTCLAS3.0采用词库的方式来进行分词,每个被切分出来的词都会被标以词性。示例步骤及程序见参考示例。
(3)参考示例
在eclipse中配置好相关环境,其中中科院提供的ICTCLAS30类的代码如下:
package ICTCLAS. I3S.AC;
import java. io.*;
public class ICTCLAS30{
/* ICTCLAS30.dll中的函数接口*/
public native boolean ICTCLAS_Init(byte[]sPath);
public native boolean ICTCLAS_Exit();
public native int ICTCLAS_ImportUserDict(byte[]sPath);
public native byte[]ICTCLAS_ParagraphProcess(byte[]sSrc);
public native boolean ICTCLAS_FileProcess(byte[]sSrc-Filename,
byte[]sDestFilename);
public native float ICTCLAS_GetUniProb(byte[]sWord);
public native boolean ICTCLAS_IsWord(byte[]sWord);
public native byte[]nativeProcAPara(byte[]src);
/*静态加载ICTCLAS30.dll*/
static{
System. loadLibrary("ICTCLAS30");
}
}
然后再建一个测试类TestICTCLAS30. java:
package cn.edu.whu.sim. ictclas3test;
import ICTCLAS. I3S.AC. ICTCLAS30;
public class TestICTCLAS30{
public static void main(String[]args) throws Exception{
/*实例化一个ICTCLAS30对象*/
ICTCLAS30 testICTCLAS30= new ICTCLAS30();
String argu="";
/*如发现user. lic文件不合法,初始化将失败,这里需要注册获得使用许可*/
if(testICTCLAS30.ICTCLAS_Init(argu.getBytes("GB2312"))== false){
System.out.println("Init Fail!");
return;
}
System.out.println("Init Success!");
String str="金穗贷记卡网络服务全新升级改版,点击查看更多精彩!";
byte nativeBytes[]=
testICTCLAS30. ICTCLAS_ParagraphProcess(str.getBytes("GB2312"));
String nativeStr= new String(nativeBytes,0,nativeBytes. length,"GB2312");
System.out.println("导入用户词典前:"+ nativeStr);
String userdict="userdict. txt";
/* ICTCLAS_ImportUserDict方法导入用户自定义的词典,返回词典中词条的数目*/
int Count=
testICTCLAS30. ICTCLAS_ ImportUserDict( userdict.getBytes("GB2312"));
System.out.println("用户词典词条数:"+ Count);
nativeBytes=
testICTCLAS30. ICTCLAS_ParagraphProcess(str.getBytes("GB2312"));
nativeStr= new String(nativeBytes,0,nativeBytes. length,"GB2312");
System.out.println("导入用户词典后:"+ nativeStr);
}
}
程序的运行结果为:
Init Success!
导入用户词典前:金/b穗/b贷/v记/v卡/n网络/n服务/v全新/b升级/vi改版/vi,/wd点/qt击/vg查看/v更/d多/a精彩/a!/wt_
用户词典词条数: 3
导入用户词典后:金穗/n贷记卡/n网络/n服务/v全新/b升级/vi改版/vi,/wd点击/v查看/v更/d多/a精彩/a!/wt_
上述程序对一段中文进行了切分和词性标注,实现了中文的分词。根据以上步骤,就可以构建用户词典对相关中文文本文件进行分词实验并查看其效果。
(4)结果分析
在用ICTCLAS3.0分词的程序中,在ICTCLAS30类中加载了DLL,然后在Test测试类中实例化一个ICTCLAS30对象,对一段中文进行分词。这里分为两种情况来分词,第一种方法就是默认使用ICTCLAS自带的词典进行分词,结果显示像“贷记卡”、“点击”这样的词没有当作整体切分出来。第二种方法中加载了一个自定义的用户词典,包含金穗n、点击v、贷记卡n这3行自定义的词条和词性,结果显示加载用户词典后这些词被成功切分出来。
除ICTCLAS的分词组件外,Java方面还有很多开源的分词组件,但是中科院的ICTCLAS无疑是中文分词方面的权威,它经过不断的修订和内核升级在速度和精度上得到了很大的提升,它独特的词性标注在一定程度上提高了分词的准确率。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。









