



【摘要】:基于领域本体的语义检索系统的设计核心是引入领域本体层作为匹配和推理的核心部件,与传统的检索方法相比,增加了本体检索推理层,其工作机理如图6-8所示。本体的查询结果——“齐民要术”将作为二次检索词对文献资源库进行检索,那么含有“齐民要术”字样的资源也会被系统查询出来。图6-7 《齐民要术》的属性图图6-8 基于领域本体的语义检索设计原理
基于领域本体的语义检索的设计原理_领域本体的半自动构建及检索研究
6.3 基于领域本体的语义检索的设计原理
传统的信息检索方法是将用户输入的检索关键词按照字面匹配的方法在文献资源库中检索目标结果,检索系统仅仅将关键词作为符号,无法理解其语义含义。例如,作者检索“北魏农书”,那么传统的检索系统仅能返回给用户含有“北魏农书”字样的检索结果,而只含有“齐民要术”的检索结果将无法被系统所识别。
基于领域本体的语义检索系统的设计核心是引入领域本体层作为匹配和推理的核心部件,与传统的检索方法相比,增加了本体检索推理层,其工作机理如图6-8所示。领域本体在构建的时候已经对该领域的概念进行了分类,每个类别下有具体的实例,每个实例赋予了一定的属性关系。仍以“北魏农书”的为例,在领域本体中有“农书”这样一个类,“齐民要术”作为该类的一个具体实例,被赋予了时间为北魏、作者为贾思勰等一系列的属性,图6-6是《齐民要术》在本体库中的一段简化代码。图6-7为《齐民要术》的属性分布图,图中的每个节点均可以作为检索点。

图6-6 《齐民要术》在本体库中的部分代码(省去了部分不相关的代码)
系统在获得了用户的检索关键词之后,通过语义推理以及RDQL语句的构建,将会对本体库发出“查询时间属性为北魏的农书”这样的指令,如果在本体库中存在这样的实例,那么该实例就会被检索出来,从而使得计算机“理解”用户是查询“齐民要术”。本体的查询结果——“齐民要术”将作为二次检索词对文献资源库进行检索,那么含有“齐民要术”字样的资源也会被系统查询出来。

图6-7 《齐民要术》的属性图
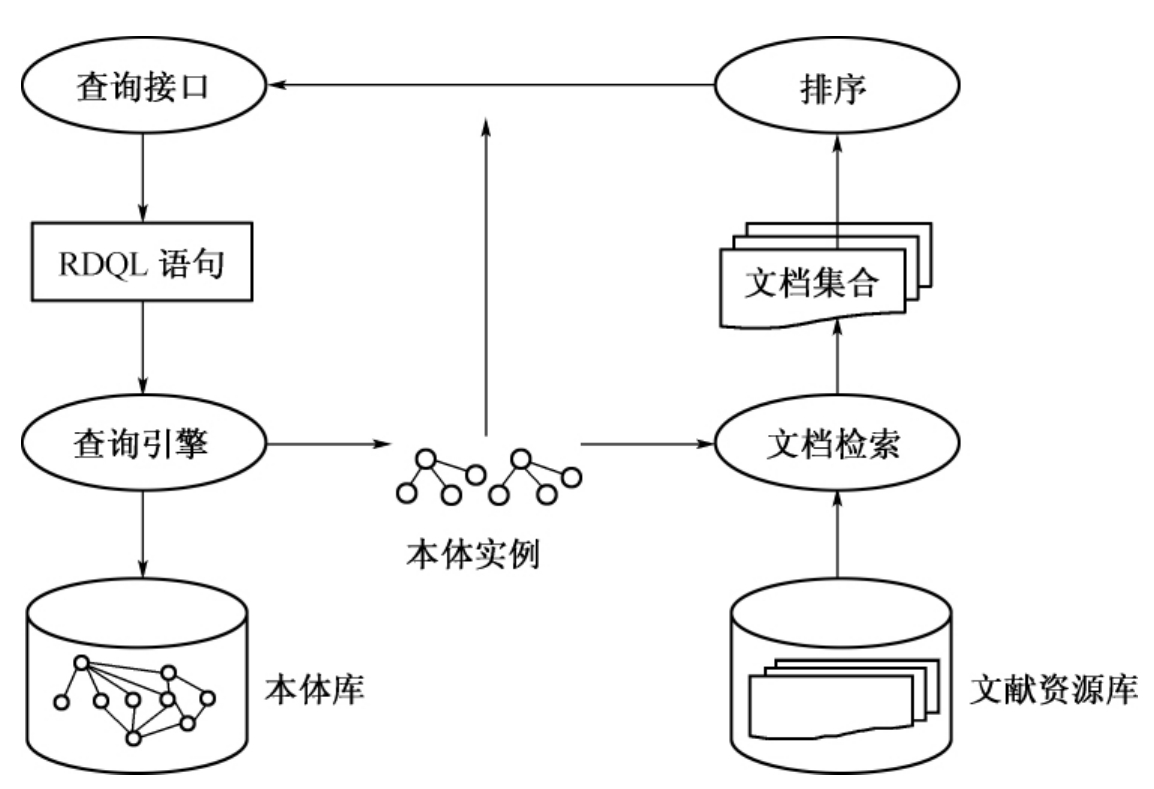
图6-8 基于领域本体的语义检索设计原理
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。









