



6.2.2 常规方法存在的问题
(1)样本规模小
由于样本的规模小,具体会产生三个问题,分别说明如下:
①测试结果置信度小
前人对关键词-分类号的相关性研究中,都是以某一个小类的数据作为样本,在进行实验统计比较分析时,数据量很小,测定结果的置信度就太小。例如,张雪英利用MI和Log L方法研究相关度时,样本仅为F83、F82类,样本空间为181023,而测试样本空间为203,占总样本比率仅为0.114%,很难说明两种方法的优劣;薛鹏军在对《中国图书检索系统》数据(MARC)的分类号进行控制时,采用MI和Log L方法进行对比实验,其样本空间仅为47,置信度太小。
②最大似然估计(MLE)误差大
由于样本规模太小,使得P(A|B)、MI、Log L等方法的测量误差加大,影响实验结果。
最大似然估计的原理是:假设一个单词W在语料库中出现的概率P(W)符合二项分布规律,则当语料库容量N足够大时,可以期望单词W将出现N*P(W)次,从而得到P(W)的估计值为:
![]()
其中:f(W)为单词W在语料库中出现的频度。
这种方法简单而实用,在许多情况下都能得到比较合理的估计。但是,如果样本规模太小,一个关键词在语料库(标引经验数据)中的概率将会发生偏离二项分布情况,使得公式(6-1)成立的误差加大,从而影响实验结果。
③产生“零概率”事件
由于样本规模太小,即某一类事件在当前小样本没有发生,会使得某些关键词与分类号的对应情况不会发生,产生“零概率”事件。在标引经验知识库中,由于关键词与分类号存在多种不确定的关系,如一对一、一对多、多对多等关系,一个关键词可能会分散在若干个跨度很大的类别中,若样本过小,这种现象的发生频率很小,会影响关键词与分类号的真实对应情况。
在文本自动标引和分类系统中,中文经济类标引经验库规模达200万,测试样本空间也将增大,这样不但可以提高结果置信度,同时最大似然估计误差也会减小,“零概率”事件会大大减少。
(2)忽略了测量方法之间的联系
在利用P(A|B)方法、MI方法以及Log L方法时,没有考察这几个方法之间的联系。实际上,它们是存在一定的联系的。例如:假设a为分类号与关键词同时出现的事件的概率,b为关键词出现而分类号不出现的事件的概率,c为分类号出现但关键词不出现的事件的概率,d为两者都不出现的事件的概率,则有:
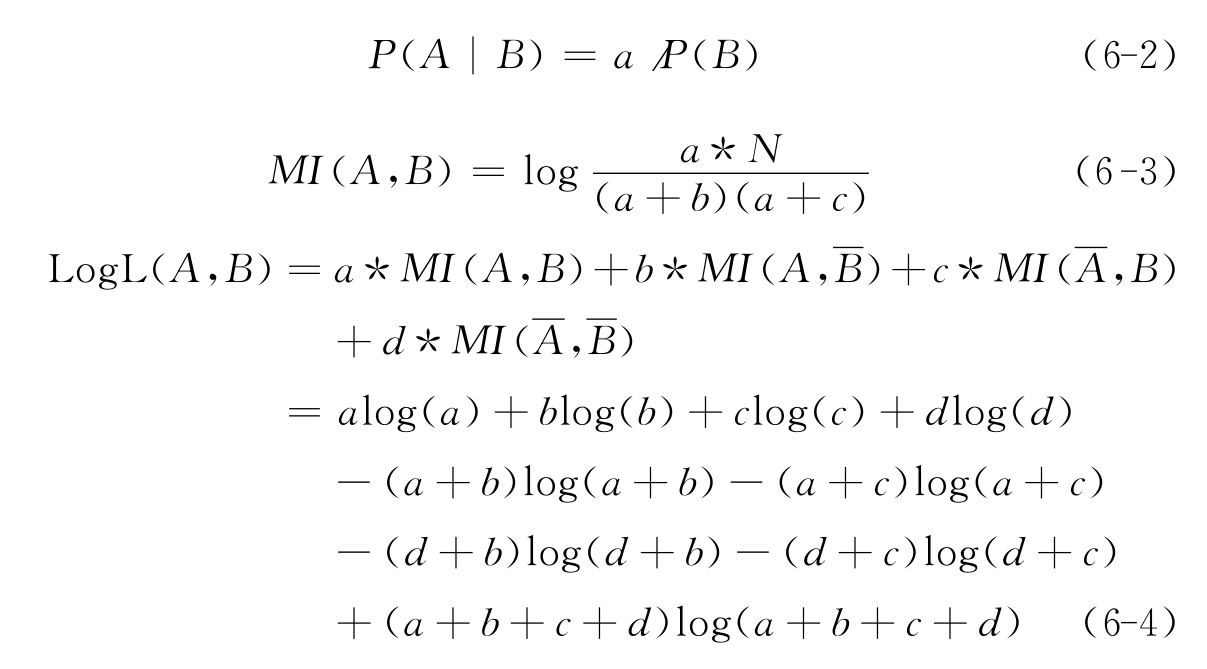
其中:P(B)为分类号出现概率;N为样本空间大小。
从公式(6-2)~(6-4)可以看出,三种度量方法是有一定的联系的,它们都和分类号与关键词的并发概率(或共现概率),即a,有很大关系。因此,在考察分类号与关键词的相关性时可以综合这些方法,加大a的权值,以发现最相关的关联关系。
(3)关键词-分类号匹配规则存在的问题
通过对标引经验知识库中分类号和关键词对应形式的考察,发现分类号和关键词对应的形式有如下几个特点:
①标引质量差异大
中文MARC采用《中国图书馆分类法》(CLC)和《科图法》进行分类标引,采用《汉表主题词表》或《中国分类主题词表》(《中分表》)进行主题词串形式的主题标引,MARC标引数据标引模式较固定、可靠,标引质量较高;《中文科技期刊数据库》(《中刊库》)使用CLC进行分类标引,采用散标形式的关键词进行主题标引;《中文社科报刊篇名数据库》(《社科库》)采用CLC进行分类标引,参照《中分表》,用词串形式进行主题标引。
举例说明如下:
表6-1 标引经验知识库中的关键词—分类对应形式举例
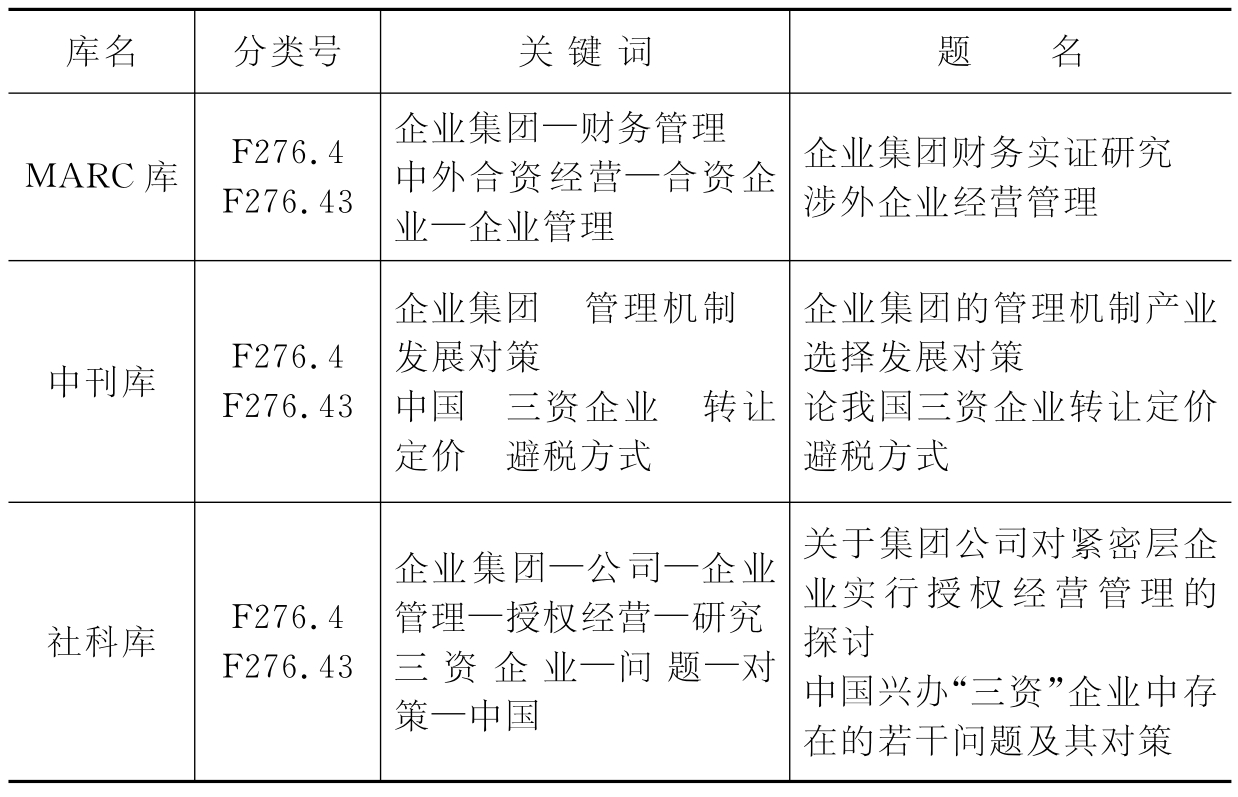
从表6-1可以看出,MARC标引质量可靠性较高,而《中刊库》、《社科库》的标引质量不高,并且存在很多的不规范的标引,如《中刊库》中,对题名为《论我国三资企业转让定价避税方式》的文本的标引结果为:“中国#三资企业#转让定价#避税方式”。显然“中国”这一标引词排序不符合显著性规则,应将其排在关键词序列最后;《社科库》中对题名为《中国兴办“三资”企业中存在的若干问题及其对策》的文本的标引结果为:“三资企业#问题#对策#中国”,显然应将其中的通用词“问题”、“对策”过滤掉。
②标引关键词排序无明显规律
通过对《中刊库》、《社科库》和其他语料库的标引结果的调查统计发现:标引关键词对主题表达能力的大小与其在关键词序列中的位置无明显规律。薛鹏军在进行关键词与分类号的匹配规则研究时,确定匹配规则为:依据标引词(串)所含词位置的不同,给定其权重分别为0.4、0.3、0.2、0.1,即第一个词位置权重为0.4,第二个词位置权重为0.3,其余以此类推[6]。显然,这一匹配规则有悖于真实情况,并且尚有其他不合理之处。权重方案应为一均衡体系,即权重之和为1。他给出的权重方案是针对4个关键词以内的情况,对于1、2、3个关键词的情况是不适用的,并且,如前所说,本身权重比率方案还是基于主观认识,缺乏说服力。张雪英等是采用四种模式,即:分类号与标引词意一一匹配(1∶1)、分类号与所有两个相邻词组成的词串进行匹配(1∶2)、分类号与所有三个相邻词组成的词串进行匹配(1∶3)、分类号与所有四个相邻词组成的词串进行匹配(1∶4),来进行分类号与标引词的匹配。显然,这种方法没有考虑到不同位置、不同词长的关键词对主题的表达能力是不同的。因此必须设计一个比较科学的权重方案。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。











